

很多企业因为业务需要建设了自己的标签库,但是当标签成千上万的时候,我们就要问自己一个问题,这些标签真得都有人用吗?用的情况怎么样?
在大多数公司,成千上万的标签虽然在某种程度上是数据服务能力的象征,但到最后往往成为了一种负担,只管杀不管埋的现象太普遍了!
比如现在我们的标签每天的调用量几千万次,但正如很多人想的那样,标签多可不一定是好事,今天就来谈一谈。
跟大家一样,我们碰到的标签的主要问题包括五大方面:管理问题、信任问题、效果问题、优化问题、系统问题。
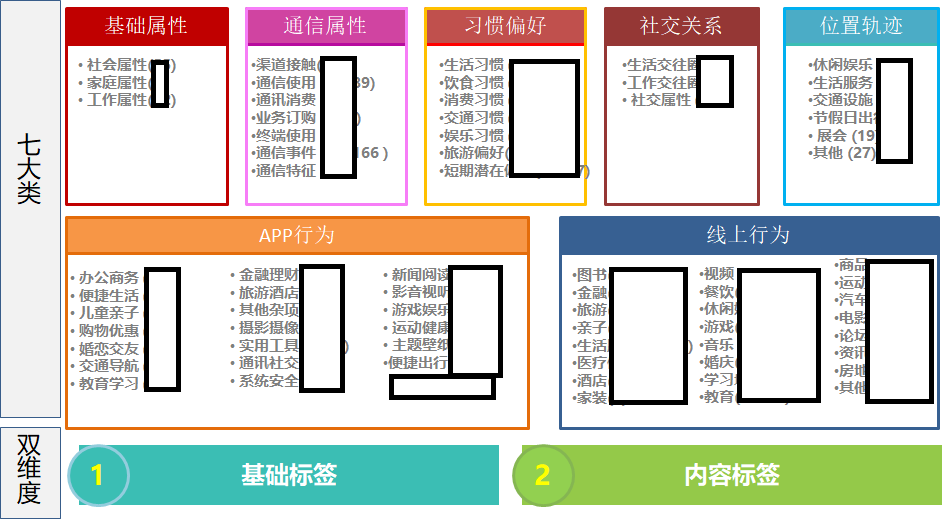
1、管理问题:标签太多缺乏规整,不知道选哪个,如下图所示,各种极易混淆的区域位置标签肆虐,个性化标签就要统治全世界了!
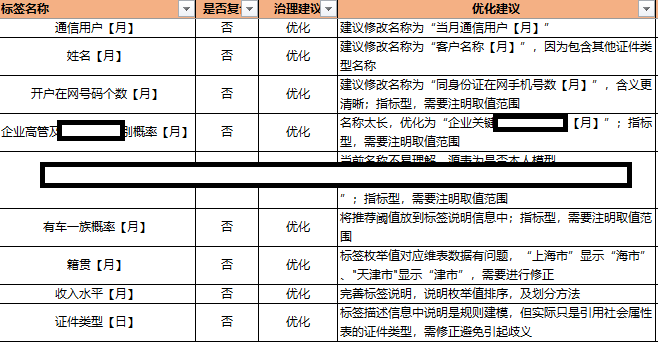
2、信任问题:标签的命名和解释性太差,可远观而不可亵玩,如下图都是标签命名或解释不清楚的示例,最终会影响用户的使用体验。
3、效果问题:标签的营销效果不可见,缺乏可比性,不敢用的现象普遍存在。
4、优化问题:虎头蛇尾,建设的时候效果还行,但却没有持续的改善机制,环境和数据的变化导致效果持续下降。
5、系统问题:标签的查询繁琐、生成时间晚、查询性能低下等等,总之一句话:系统不给力。
正如数据治理一样,标签库如果任其按照需求驱动的模式去任意发展,最终将变得越来越混乱直至完全失去价值,而这个过程往往是温水煮青蛙的。
今年我们启动了标签治理工作,这里就来谈一谈具体做法,希望于你有所启示:
一、标签体系盘点
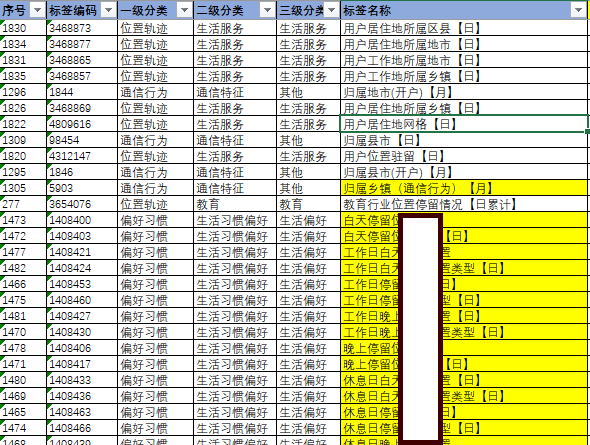
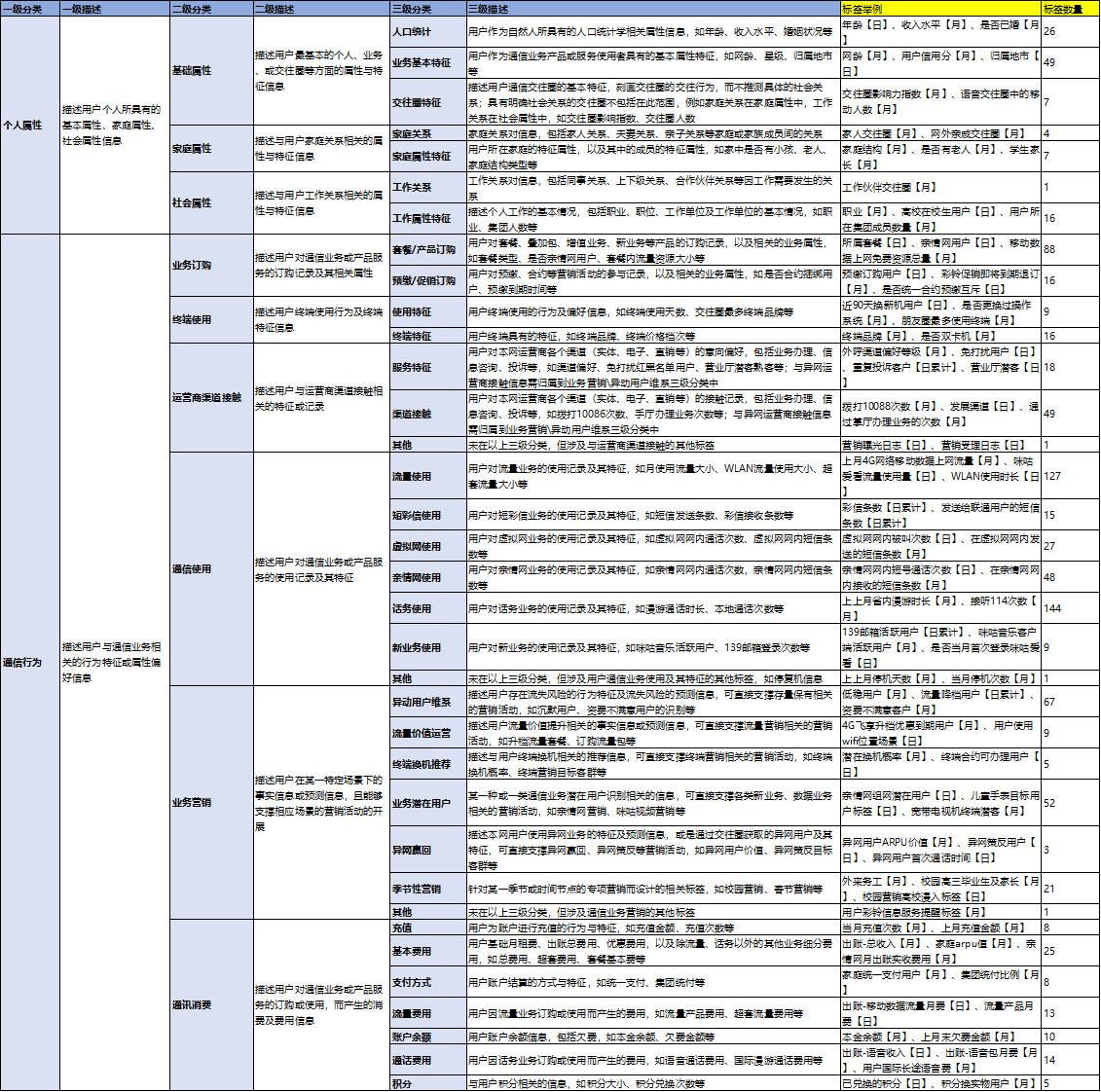
首先当然是搞清楚标签的现状,包括分类、子类、名称、更新方式、使用次数、更新时间、责任人等等,例如得到如下的表格,这是标签治理的起点。
标签体系
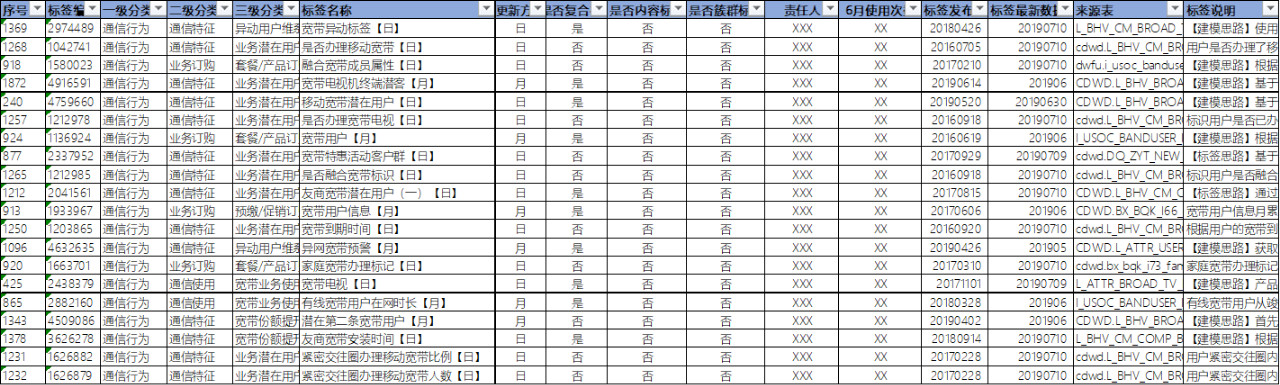
标签清单
二、确定治理优先级
面对七大类别的百万标签,不可能眉毛胡子一把抓全部都去治理,肯定要从现状中找到关键点,然后排定优先级。比如我们认为基础标签的使用频度最高,而其中又以位置轨迹、通信属性、个人属性为最,因此第一阶段重点就进行这些类别标签的治理。下面是个计划示意,当然每个阶段的具体优化方式是一样的。
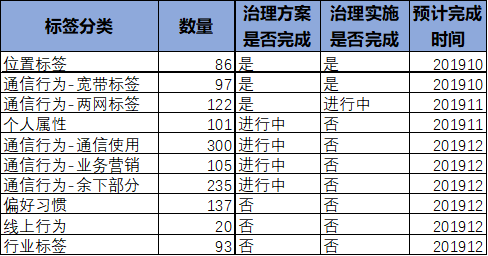
笔者觉得,在治理中不要有毕其功于一役的想法,比如应该先把位置标签的治理当成试点,治理完了看效果,如果有效,就总结经验,继续下一批,由此迭代,而不是全部治理完了再看,这样可以有效降低治理的风险,因为整个实施周期太长了。
其实在启动标签治理工作的时候,作为老兵的我,也是忐忑不安的,因为缺乏信心,也是摸着石头过河。而不少企业的数据治理工作一上来就说要完成整个报表体系的治理,完成整个指标体系的治理,这是很难的。不信你接着往下看。
三、标签体系优化
1、聚合标签
既然是治理,为什么要新增标签呢,因为要进行标签的合并规整,规整后的标签自然成为了新的标签。
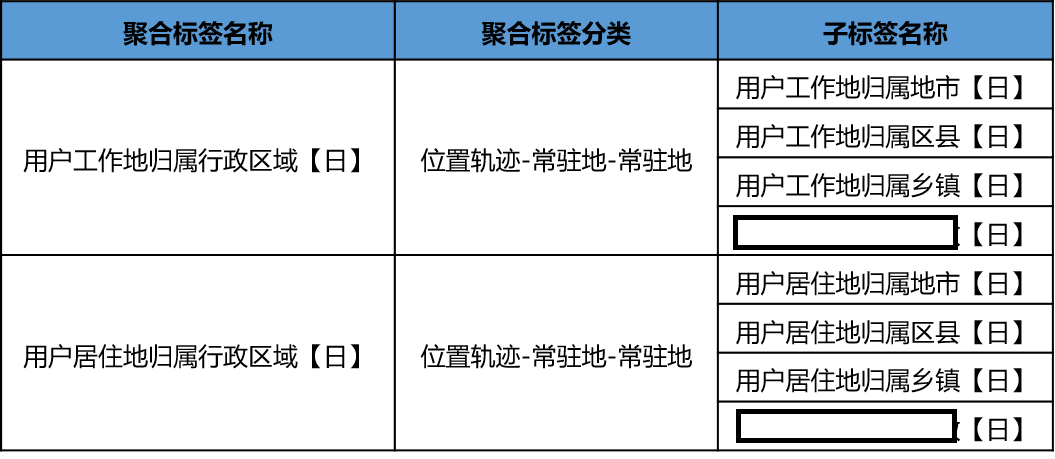
比如原来有四个工作地位置标签,分别是用户工作地归属地市【日】、用户工作地归属区县【日】、用户工作地归属乡镇【日】、用户工作地XXXX【日】等等,但你会发现用户在使用的时候往往无法一步到位选择到自己所需的标签,因为选择太多、粒度太细,而这种现象普遍存在。
因此新增了聚合标签这个概念,就是做一次封装,最后面向用户展示的标签被整合成一个,即用户工作地归属行政区域【日】,而更细粒度的标签就定义为子标签,这是一种自顶向下的设计方法,在不大动原有标签体系的情况下,可以给用户更好的使用体验,当然各家有各家的做法,我们只是给出了一种解决方案,如下图所示:
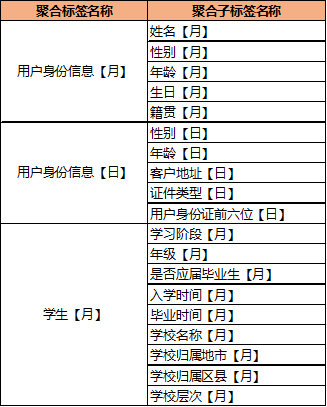
同样身份类的、学生类的标签也统一定义成了聚合标签,如下图所示:
2、优化标签
虽然我们在上线标签的流程中有元数据的录入管理规范,但实际运营中往往是形式大于内容,存在大量的标签命名的歧义、不知所谓的标签说明等等,这些都极大的影响了标签的使用体验,因此这些都是标签治理的重点。比如名字的修改:
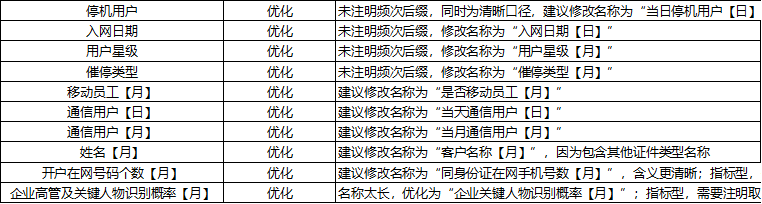
比如取值的修正:

比如描述的修正:

还有就是有些标签效果差或者很少人使用,但还是非常重要的,比如潜在集团客户标签等等,这个就需要纳入标签专项优化的排期。
3、下线标签
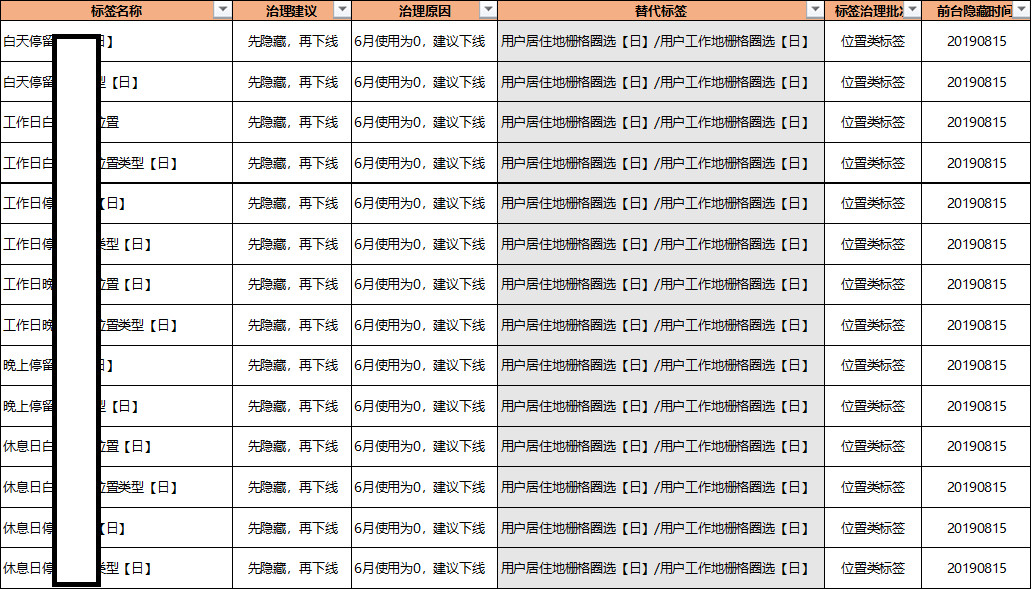
无人使用的标签直接下线,使用频度很少的标签先隐藏再下线,下线后相关的脚本和调度也下线,一方面可以减少对用户的打扰,另一方面还是可以释放资源,这是真正的降本增效,如下图示例:
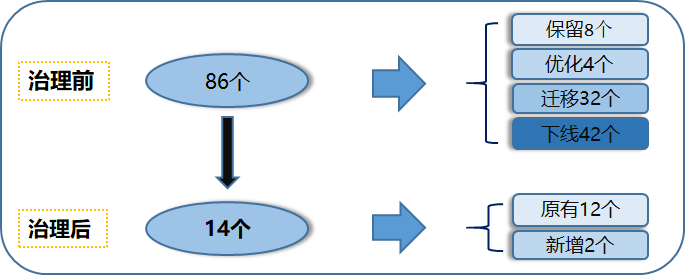
比如位置类标签,治理前有86个,治理后就只有14个了,如下图所示:
又比如通信宽带类标签,治理前36个,治理后14个,如下图所示:
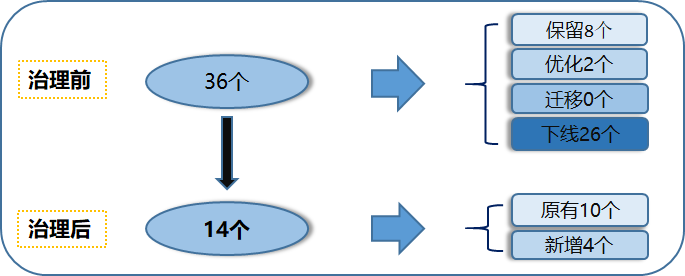
笔者以前在治理报表的时候有个经验就是:一个业务一张报表。标签虽然没法做到,但大致原则是一样的,总是要去优化和传承,不要总是另起炉灶,比如宽带类标签以后就可以针对性的只运营5个,如下图所示:
4、阶段性效果
启动标签治理的时候我们曾经强调要层层推进,分阶段性的去看效果,但实施中还是没有很好的贯彻这个原则,应该是工作的惯性吧。
比如位置类标签治理完后,并没有马上去做新位置标签的运营推广,甚至没有给出任何的评估数据,而是急于去做下一阶段的治理工作。
团队最近则有了明显的改善,比如以下是位置类标签治理后的初步效果数据,注意这是在没有做任何推广下的点击率的自然提升。
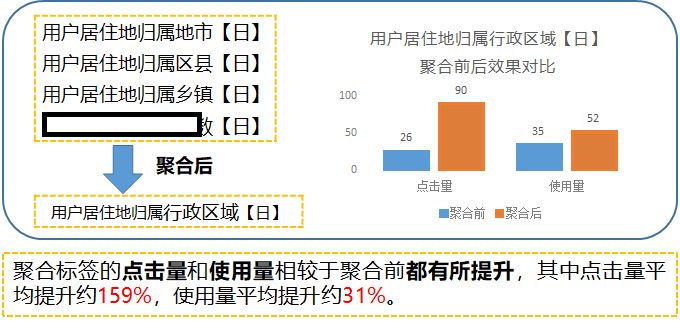
很多治理工作之所以越做越苦,往往是因为这个治理工作的付出跟用户感知的提升并不匹配,尽快获得效果不仅仅是持续迭代的问题,更是进一步推进工作的强心剂。
四、标签库优化
标签治理不仅仅是指标签本身的治理,也包括相关系统的同步改造和优化,比如标签库功能完善、标签生成提速、标签质量管理等等,这就需要有全局视野,当你启动这个工作后,会发现事情比你当初设想得要复杂的多。
1、功能优化
为了支持新的标签模式,比如聚合标签,会涉及到标签库的管理、查询、统计、展示等一系列相关功能的改造;为了更好的宣传推广标签,就需要进行布局和体验的优化,比如增加搜索能力,增加侧边栏标签推荐,增加标签地图等等。
2、性能优化
首先,是关于标签生成及时性问题,由于标签数量众多,而且往往是批量生成的,比如基于同一张宽表,批量生成的核心问题就是同一批次的标签在业务上的优先级其实是不同的,这就意味着要么技术上追求方便,要么去牺牲业务上的体验。
如何平衡业务和技术,如何拆分宽表,如何设定优先级,如何精确调度,就成为标签数据提速的核心问题。
其次,是关于标签查询的速度问题,比如要能即时知道客群的大小,就需要ES引擎的支持,这一功能的改善的价值很大,客户有时候选择客群其实是个探索的过程,而探索对于性能的要求特别高。
最后,是关于标签对外开放的问题,比如位置类的API往往对于后端的统计性能要求非常高,需要专门的数据库进行支撑。而对于一些特殊查询API,也不是简单用K-value这种形式可以支撑的,比如需要判断某个号码是否在某个用户群里等等。
3、监控优化
标签库可以认为是一个应用产品,但其数据的分量特别重,而大数据平台的数据质量管理体系一般仅负责推送数据接口的质量,而到标签粒度的质量监控往往无暇顾及。
这就需要标签库主动推进这个体系的完善,现实中往往是要等到某个标签报障了才去核实原因,这也是标签治理中的重点问题。
五、机制的优化
标签治理不是一棍子买卖,因为即使这一次治理好了,但如果没有机制和流程的保障,最后还是会走向混乱,因此在治理中同步建立和优化相关的机制和流程是至关重要的。
笔者这里列几个关键点:
1、责任到人
就是企业里任何一个标签都应该有归属的组织和负责人,比如我们整个标签体系都是按照类别归属到个人的。
一个明显的好处是用户只要在标签库看到有疑问的标签,直接找负责人就可以了,这样比较扁平化,而且处理的效率会高,也有利于中台组的人员有事实上的业务驱动力。
2、管理到位
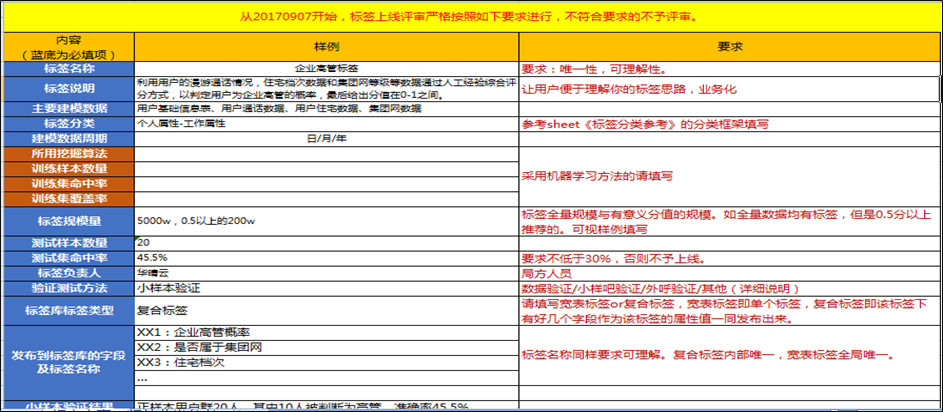
无论是需求、开发、上线或运营环节,都建立了初步的规范,比如对于需求,要明确搜集的渠道和方式,包括主动和被动等等;对于开发,要明确分类规范、命名规范,描述规范(建模思路、使用场景、生成周期、使用方式、标签效果(正在建)),实现规范(纵表,宽表、聚合)等等;对于上线,则要明确标签审核的模板等等,以下是上线标签需要填写的模板示例:
3、运营有效
需要建立专门的标签运营团队,制定标签运营的相关管理方法,包括效果数据如何进行采集分析、重点标签怎么进行跟踪评估、标签问题如何处理及反馈等等。
运营的统一收口能改变无序的状态,不求一时的亮点,但一定要能客观公正的通过数据评估实际情况,从而体系化的推进各方开展工作。
原来的一大问题就是临时拼凑的运营团队(比如项目团队,建模人员等等)往往虎头蛇尾,开始推广的时候很积极,但一旦推广完成了就再也没人理了。
很多时候大家以为很好的标签几个月后的效果数据其实已经变得惨不忍睹,但却没人知道,所谓亮点工程。但运营其实是非常专业的事情,BI时代这种亏其实吃得太多了,但就是不长记性。
从某种角度来讲,一个标签就是一个产品,运营的压力其实是很大的,假如它真的在生产中得到广泛使用的话。你没感觉到压力往往是因为没人在意你做的东西。
关于标签,笔者近些年的一个切身体会就是:做成一个标签难度不大,但要运营好这个标签所付出的代价远超建设,由于重建设而轻运营的思想普遍存在,因此我们总是会面临困境,希望这次能打破这个魔咒,从而为企业创造更多的价值。
如果你从事标签相关工作,也拥有上千的标签体量,相信一定能Get到我说得点,希望于你有所帮助!
文章来源: 与数据同行 微信公众号