

B站大数据历史
- B站大数据成立历史
- 公司流量快速增长、数据必然爆发式增长
- 以增加资产解决资源瓶颈已不是长期方案
互联网公司发展到一定阶段,各种场景的数据需求会越来越多,业务通过数据进行快速迭代、决策,已成为各家互联网公司必备的能力。要解决猛增 数据的清洗 以及 海量历史数据的加工,势必要引入大数据能力。B站是 09 年成立的互联网公司,但整体大数据体系的建设相对较晚,17年成立大数据团队,19年才开始规模化的建设,随着公司快速发展,数据规模也在爆发式的增长。

(图一 往年大数据规模)
截至 23 年 B站数据已经达到 EB + 超大规模体量。爆发式的增长,长期通过采购服务器来满足资源瓶颈,已不切实际。我们需要有一套长期地、合理的资源管理模式。既能满足业务增长过程中的数据使用,也能有效控制公司在大数据体系整体投入的预算、费用。 但要达成预期数据治理效果,我们将要面临的巨大挑战,包括:
- 多个业务线,各自管理数据,无统一管理体系;
- 业务数据、技术数据混合在一起;
- 资产归属认证体系缺失,存在大量无主数据;
- 数据上报无统一标准、格式等。
如何能有效地解决现有问题?21 年下半年,数据平台开启公司大数据治理之路(立项 —— 望楼 1.0)。
“望楼”项目启动,
存储淤泥中从0到1的挣扎
望楼,是古代观敌预警、登高望远的楼阁。项目以此为名,寓意最终必须构建一套能从高处全盘掌控数据资产情况,长期地监控异常、及时地警示风险、权威地解决问题的治理框架。
在立项时,有两个问题是首要考虑的:
(1)如何启动治理这件事 ?
(2)如何让用户改变习惯和观念,参与资产治理 ?
问题一:如何启动?
其一,让资产元数据铺开治理的
第一块砖
资产治理本质是一个为业务赋能的过程。它要先有业务数据建设,再谈为业务赋能。在具体的实施上,映射为先做资产元数据模型,再建治理指标体系。
- 资产元数据模型
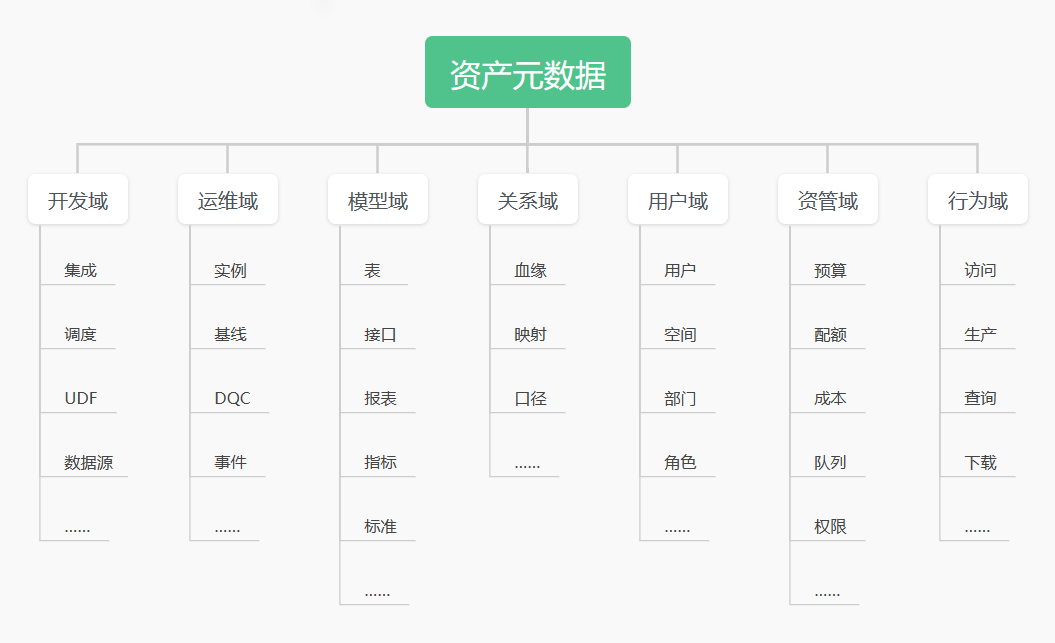
(图二 资产数仓数据域)
建设之初,公司的大数据资产规模、明细,都是一个混沌的状态。
这个阶段需要自下而上的建设路线,先圈定平台主要数据资产项(hive表、调度任务),再列出资产项生命周期各环节的业务过程(建表、建任务、发布、运行、授权、消费、下线等),输出一个较完整但不钻细节的元数据主题。这些数据输出,是为了支撑起资产盘点、问题发现、治理策略探索等初期准备工作。
当资产规模和历史问题有一定的盘点后,工作内容从发现问题转向用策略解决问题。这个阶段就要逐步进入自上而下的建设路线,以治理指标体系作为数据建设的主要需求输入,最终数据的输出,是为了治理策略执行服务。
- 治理指标体系
指标体系从来不是独立成章的,它与运营方法牢牢绑定在一起。没有运营落点的指标,产生不了价值,没有指标指导的运营,容易迷失方向。
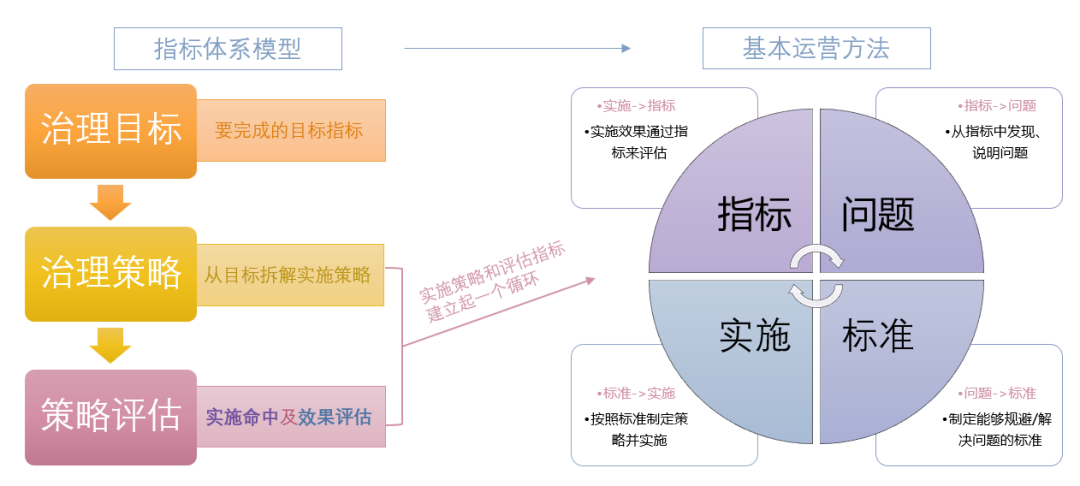
(图三 治理体系 指标<->运营联系)
B站的治理指标体系模型,由治理目标、治理策略、策略评估三者组成。
- 治理目标:指一段时间内要完成的目标指标(即北极星指标)。策略从目标拆解,所以要先确定目标指标。
- 治理策略:从目标指标拆解出实施策略。策略制定分为策略方向和实施项。
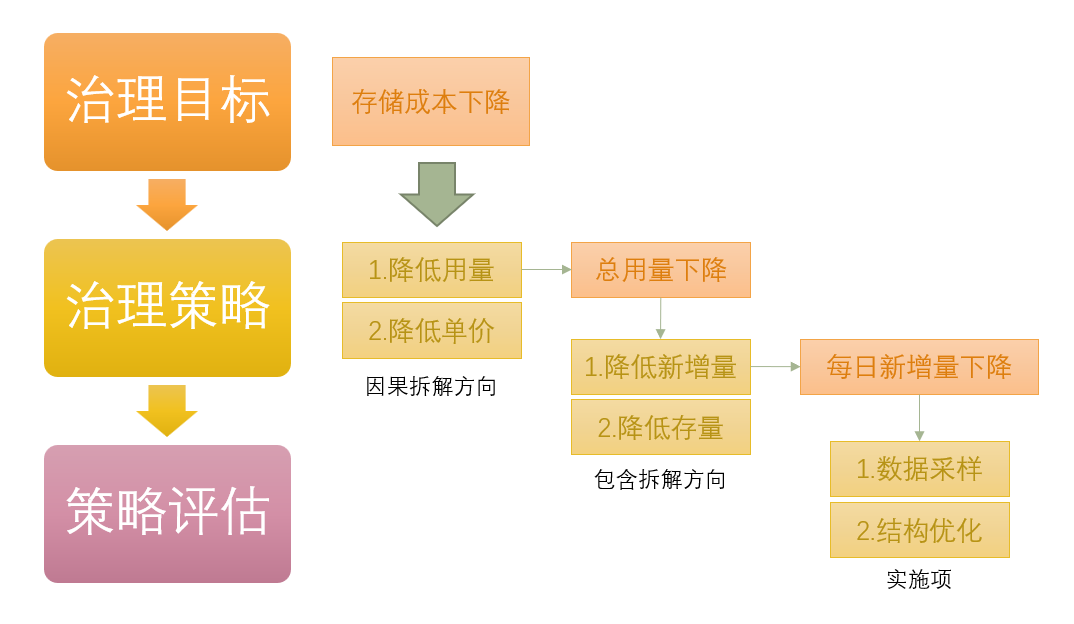
(图四 治理目标拆解方法)
- 策略评估:包含两类指标。
- 判断是否命中实施策略的问题命中指标
- 评估策略好坏、实施效率的治理效果指标
B站的治理运营方法,由指标、问题、标准、实施四项组成。
- 指标->问题:通过问题命中指标,发现资产清单中存在哪些问题。
- 问题->标准:确定问题后,建立出能够规避问题、解决问题的标准。
- 标准->实施:标准建立后,依照标准制定运营策略,并付诸实施。
- 实施->指标:实施周期后,观察效果指标,评估该运营策略与此次实施行为的效率。
其二,选择合适的发力点,让运营方法
首次转动
资产规模大,存量问题繁杂,必须先专注于一个发力点,来实践、验证数据与策略。正如本节标题所说,存储治理成为了项目的第一个发力点。
- 发力点的探索
为什么选择了存储治理?发力点要如何探索确定? 思路应当是,找到瓶颈,当前最痛的地方。
立项之初,几乎每个月都要面临存储水位到达90%以上,紧急组织数据清理的状况。同时从大数据资产的成本分布来看,离线存储也是最大单项。
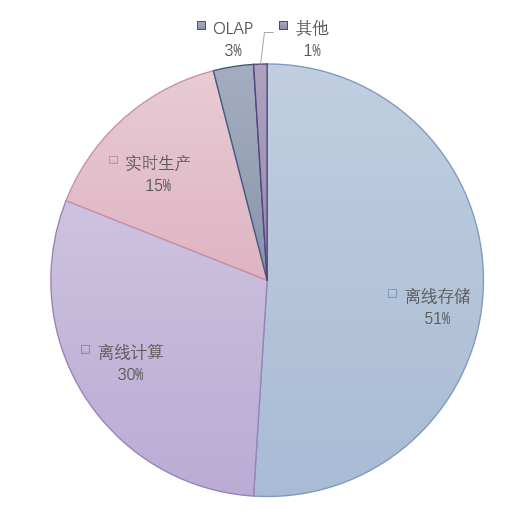
(图五 大数据成本分布)
- 存储治理阶段性目标的确定
为了让人力工时从存储水位的应急响应中释放,需要一波足够大的存储治理量,将水位降至安全线以下,并能在约半年的自然增长下,依然保持无风险状态。根据水位情况与预测增长趋势。在21年的数据试水后,我们定下22年年内优化 整体存储资源 50% 的目标。
- 存储治理策略的拆解、排序
定好目标是优化存储量,首先拆解第一层策略方向。
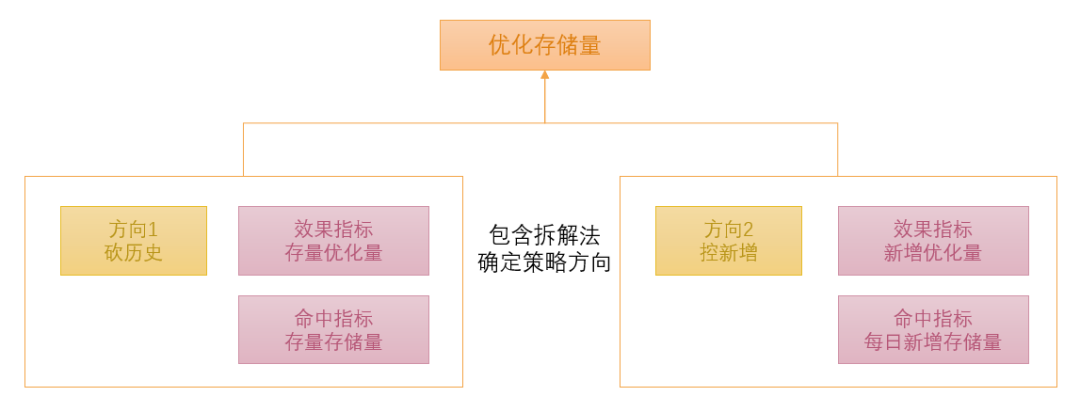
(图六 治理单项目标拆分)
我们先将视角放到历史存量方向,利用命中指标“存量存储量“,可以拉出一批存储量最高的TOP列表,分析TOP列表,找出列表中资产存在的共性问题,比如:
- 下游无使用
- TTL过长,超出该数据的时效意义
- 数据未经压缩
等。
找出问题后,针对问题做出标准定义,制定策略:
| 问题 | 标准 | 策略 |
| 下游无使用 | 无热度数据作下线处理 | 推动无热度数据下线 |
| TTL过长 | 按时效定TTL/按层级定TTL | 推动过长数据缩短TTL |
| 数据未经压缩 | 数据必须压缩 | 推动未压缩数据执行压缩 |
三项策略制定好之后,依照人力工时的投入上限,我们还需对三项策略x上万资产项的组合做好执行优先级的排序。排序以“实施成本低,效果收益高”的顺序为最佳。
- 模型与指标的建设
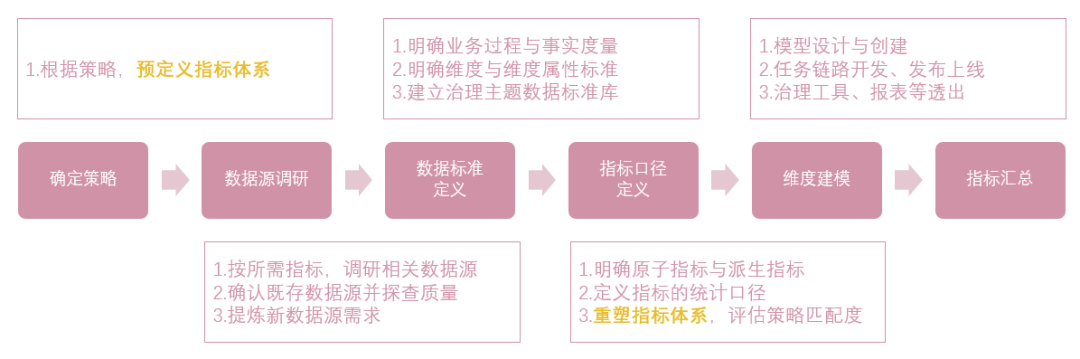
(图七 治理指标建设过程)
在策略确定后,预定义所需的指标。
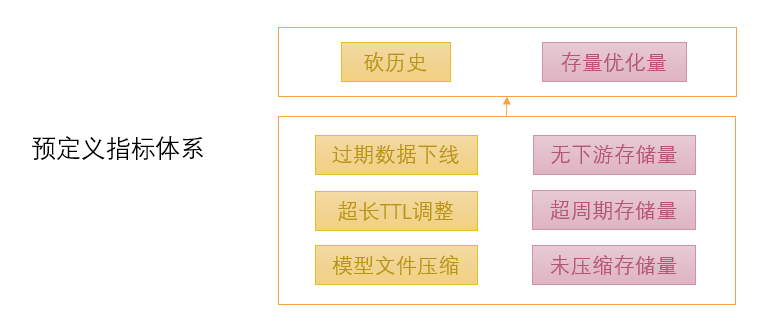
(图八 治理指标的预定义设计)
以预定义好的指标体系作为模型建设需求,做好数据源调研,确定指标统计口径。如果数据源的质量或形态不满足预定义指标的口径,则须重新定义替代指标。
同时,还需定义策略实施中关注的维度。通常,在存储治理实施中会有以下维度值得关注:
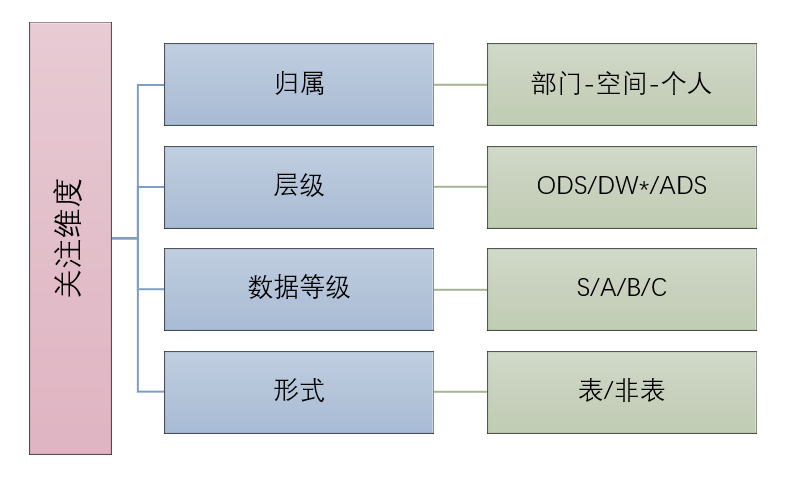
(图九 治理指标体系维度)
在不同维度下,策略可依据属性值做阶梯、特例等微调。
- 存储治理的持续化运营
按既定策略将策略指标建好后,将其投入突击性集中推进实施,或按天、按周、按月的周期性实施循环中。直至问题完全解决,或阶段性解决。
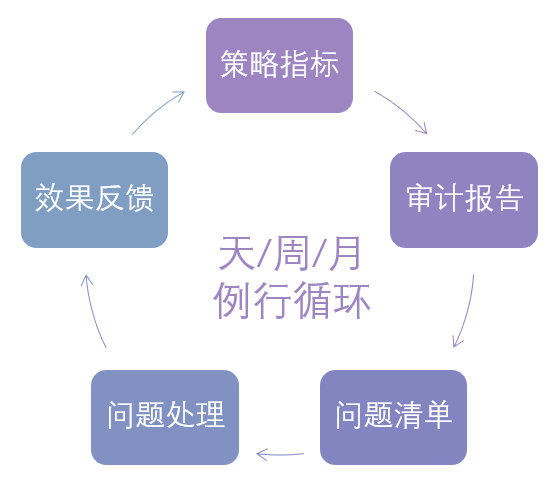
(图十 治理策略运营策略)
向问题资产项的owner发布问题清单,并通知他应当在何时完成优化。
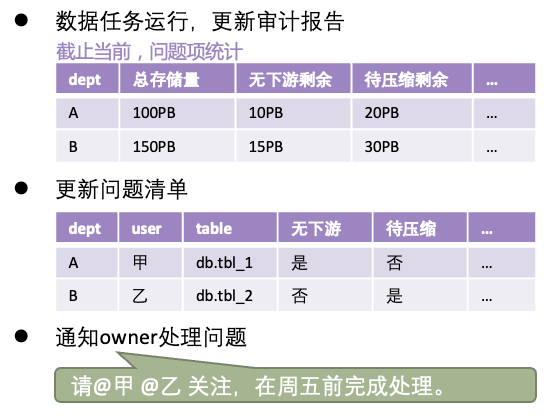
(图十一 治理策略运营案例)
当我们解决了第一批问题,依然可以继续找新的问题,定义新的标准和策略。
举例第二批问题:
| 问题 | 标准 | 策略 |
| 游离目录 | hive表meta信息删除后,游离目录必须清理 | 推动游离目录下线 |
| 超大json字符串 | 用map、struct等结构替代json | 推动超大json字符串改造 |
| …… | …… | …… |
新的问题,新的指标建设,新的策略实施,持续不断地进行下去。可以用大小两个循环来描述这种持续性。
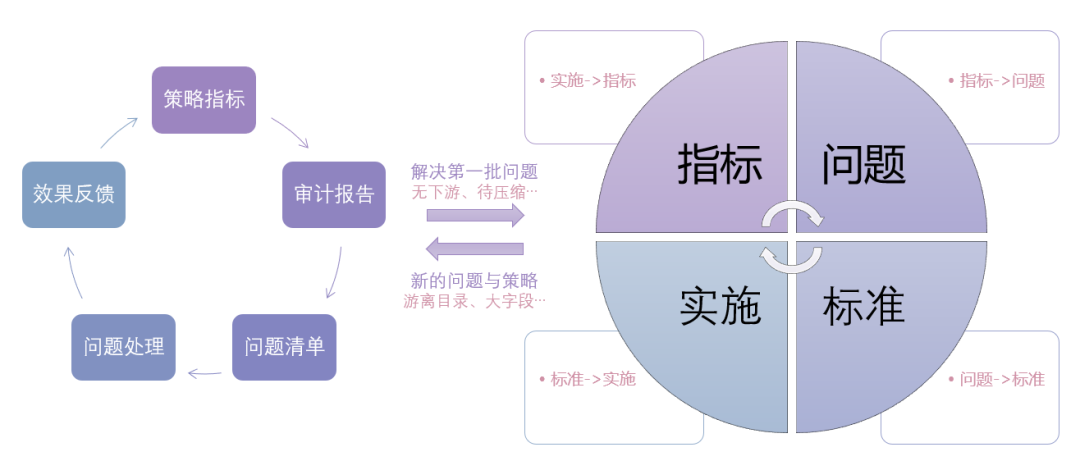
(图十二 治理策略可持续运营)
问题二:如何让用户配合?
其一,培养用户对大数据资产成本和
管理规范的意识
绝大多数用户在跑查询、做报表时,不会产生“我花了多少钱”这样的意识,也不会产生“我这个行为是错误的、不规范的“这样的意识。因此,想要用户配合成本治理的实施,首先必须将这种意识种入用户的大脑中。
花了多少钱,用账单告知。
为了让用户感知到大数据成本,同时,也为描述当前大数据平台的资产规模,我们发布了部门、空间、个人三级账单。账单以资产大项、小项分别统计,再汇总。截至目前覆盖的资产大小项包含:
| 资产大项 | 使用组件 | 资产小项 |
| 存储 | 硬盘存储 | HIVE表 |
| 硬盘存储 | 非表存储 | |
| ClickHouse | ClickHouse表 | |
| 计算 | Flink | 流计算任务 |
| YARN | 集成任务 | |
| YARN | Ad-Hoc查询 | |
| YARN | 调度项目 | |
| Presto | Ad-Hoc查询 | |
| Presto | BI工具查询 | |
| Presto | DQC | |
| ClickHouse | ClickHouse计算 |
账单的计算,应以两个准字为标准。
- 归属准
账单建设初期,由于存量资产存在大量来源不明、归属不明问题,我们遇到了不少阻碍。
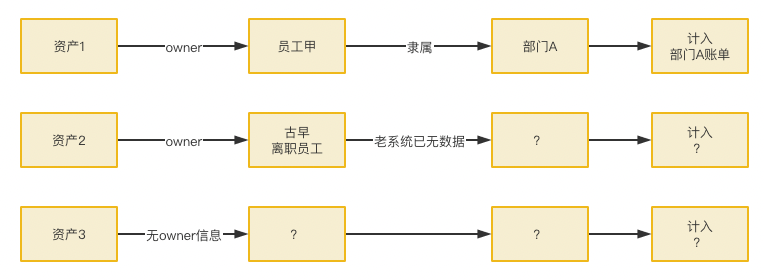
(图十三 资产归属案例一 :归属不明导致无法记账)
为解决资产归属问题:
- 严格要求后续所有新数据资产通过数据平台界面注册,记录注册者信息。
- 要求资产元数据能覆盖到数据平台支持的全部资产项。
- 杜绝由于交接异常导致的失主,重新梳理交接流程,且规定生产任务与产出数据表的owner信息保持一致。
- 推动客户端鉴权与数据平台权限打通,避免由客户端操作导致的失主或归属异常。
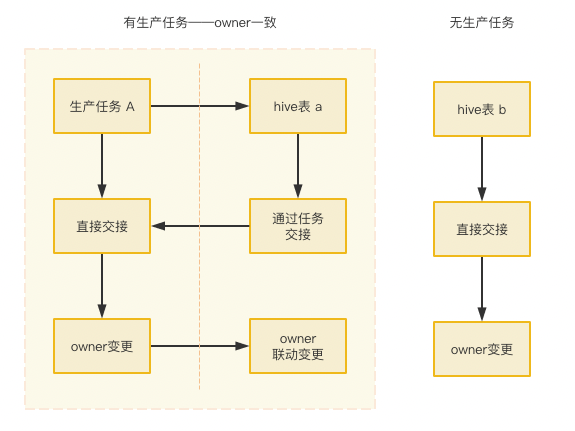
(图十四 资产归属案例二:资产交接原则)
当归属异常的入口被关闭,对历史存量,就要以一套基础的归属追溯逻辑去批量寻主,使其找到归属人、归属部门。
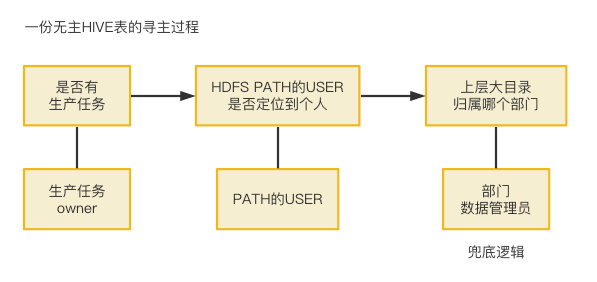
(图十五 资产归属案例三)
- 度量准
大数据资产账单的计算公式可简化为——用量 * 单价。
因此,记账准,就要求资源用量的数据源、统计任务,需要全链路的数据质量保障。
最早做账单任务链路时,流量资源、实时存储资源等大项,存在无底层组件数据源、上层数据源也不稳定,可用性堪忧的情况。这导致账单发布的头几个月,记账数据产出延迟、个别实例用量丢失等质量问题,成为家常便饭。每月账单产出前,都需要人工做二次确认,评估账单总额、部门波动是否符合预期,如有违预期,还需找出异常原因,临时设计修复方案。
到如今,数据平台已将所有资源用量数据源替换为组件底层数据,且通过常规方式入仓,上下游对其运维等级有统一的认知,保障账单产出的稳定性和准确性。
| 组件 | 用量数据源 |
| HDFS | HIVE元数据 / FSImage 日志文件 / AuditLog 日志文件 |
| YARN | Appliction运行记录信息 |
| Kafka | Audit日志 |
| ClickHouse | ClickHouse元数据 |
| …… | …… |
行为规范与否,用治理分告知。
为了让用户感知到资产管理规范,我们设计了一套评分模型,将一些基础治理项的存量或实施转化为加减分,以一个分值来体现各业务部门的治理规范水平。
治理评分模型的设计,有以下三个理念:
应当体现出平台的治理经验。是历史上经验教训的总结,是已论证确实获得效果收益的策略。能向用户普及数据治理的概念,改变用户只用不治的习惯。
应当体现出权威指导性。指标并非固定不变,会做周期性更替,每一期更替依照公司当前治理重点来调整。治理优先级为重要参考因素,将高优项纳入评分,低优项可排除出评分。
应当体现出执行上的循序渐进。同类项,随周期逐步加强要求,提高评分标准。模型规范,随周期从ODS层逐步往高层推进。超前于当前治理重点的指标可做加分项,但后期应更改为减分项。
摘录第一期、第二期的指标如下:
| 第一期 | 第二期 | ||
| 大类 | 细项 | 大类 | 细项 |
| 模型建设 | ODS模型建设率 等 | 模型建设 | 低频模型数 等 |
| 数据规范 | 模型信息完整率 等 | 数据规范 | BI工具使用规范率 等 |
| 数据质量 | 基线达标率 等 | 数据质量 | 事件反馈率 等 |
| 任务优化 | 高资源任务数 等 | 数据安全 | 越权访问数 等 |
| 资源使用 | 生命周期未配置数(单点,修改配置即可) | 资源使用 | 无效报表数(向链路治理升级,需链路分析) |
| ODS重复建设数(单点,下线即可) | 无热度模型数(向链路治理升级,需链路分析) | ||
| MySQL数据同步重复数(单点,下线即可) | ORC压缩率(执行难度加大,需改造) | ||
治理分的发布,帮助我们快速摸清公司的存量问题,控制和指导每一阶段的大方向和优先级,评估部门间的进度差异。
评分指标项获得业务部门认可后,平台与业务治理目标、利益关系达成一致,加速推进。在公司每半年的技术大会上,设置了依据治理分评选出的部门级数据治理奖项,对当个半年治理成效突出的部门予以表彰。
其二,提高用户对成本治理实施的意愿
治理实施意愿取决于很多因素,但在几次用户调研中,可以发现最大的因素在于“历史存量庞大,工时消耗过多”。用户面临数据平台交予的治理任务时,会陷入好像怎么努力也做不完的苦恼中,何况用户有自己的业务主线,不可能把工作时间全部投在治理实施上。
因此,为了提高用户的实施意愿,需要帮助用户解决:
- 做好自动化:可自动化实施的问题项,避免用户人工处理。
- 做好问题拦截:可拦截的问题不要持续新增,让用户看到彻底解决的希望。
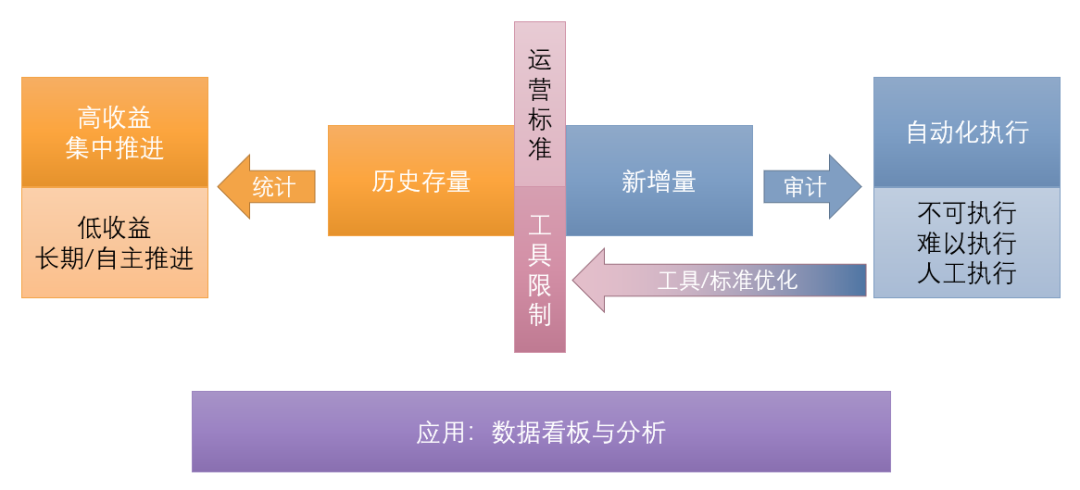
(图十六 治理工具化:工具按标准自动拦截或处理)
- 做好分类:让用户知道哪些问题可以合并处理,节省时间。
- 做好排序:不同治理项之间、不同资产之间的优先级,明确地告知用户。
- 做好功能引导:怎么执行、去哪里执行,有什么注意事项,主动将此类引导给到用户。
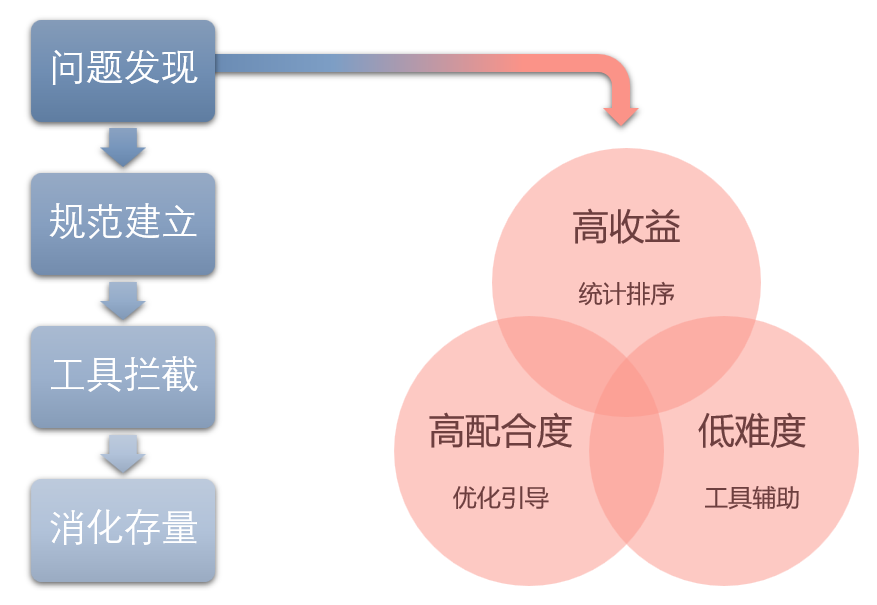
(图十七 治理工具化:治理操作引导和分类排序)
做好工时评估:让用户知道每一项工时多久,并按周期提供用户治理实施的工时统计。
| 治理项 | 问题资产数 | 预估单个工时 | 预估总工时 |
| 无热度模型 | 20 | 0.5h | 10h |
| 数据压缩 | 20 | 2h | 40h |
| …… | …… | …… | …… |
做好效果量化:治理项实施之后,得到怎样的效果收益,按周期提供给用户统计值。
| 周期 | 处理问题个数 | 治理收益 |
| 第35周 | 10 | 2PB |
| 第36周 | 15 | 5PB |
| …… | …… | …… |
阶段性成果
通过资产元数据与治理指标体系的搭建,协同账单与治理分的辅助,平台在存储治理这一单项上,两年间取得了巨大效果收益。
截止22年,已实现整体存储资源 55% 的治理,22年 全年增长速率从 21年 226%下降至34% ,累计节省B站大数据侧预算 亿级规模 ,最终超额完成整年的目标。
化被动为主动,多元化治理的蜕变
虽然望楼项目在21~22年间成功实现存储治理的巨大收益,但它依旧存在决定性的缺点与不足。其中最为突出的问题是:被动治理与单点治理。
问题一:如何化被动为主动?
发起存储治理的原因是“痛”,当痛点已经出现,水位濒临决堤,不得不投入人力去治理,这种治理模式是被动的。被动治理的弊处是,治理执行节奏、时间预期,都取决于危机的逼近,不可自行控制。它会打断业务常规工作,让执行者疲惫。
因此,将被动治理转化为主动治理,是在多元化治理铺开前必须实现的转变。
其一,提前规划长线治理目标,抢在问题
爆发前,预备好数据和策略
面对存储之痛时,计算并非不痛,只是小规模体现,或等待爆发时机。主动的第一步,是将还不痛的资源治理纳入规划。
22年Q4,我们在深入实施存储治理的同时,已对YARN、Flink、Kafka等多项资源展开瓶颈摸排、数据建设和策略预设的工作。23年H1,上述资源治理的计划全部体现在OKR目标中。
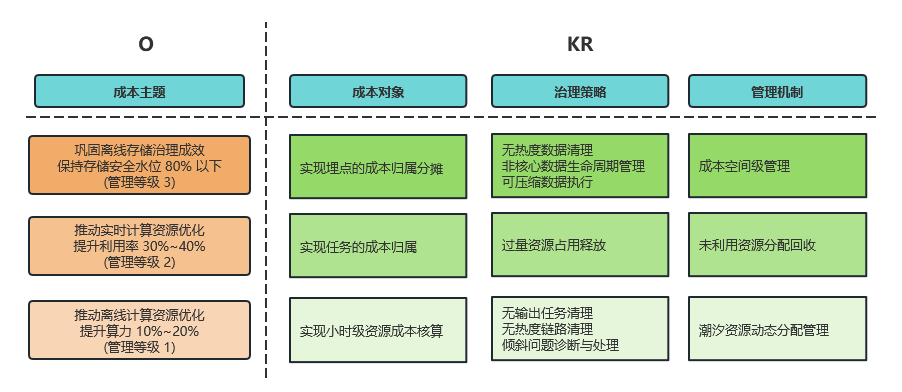
(图十八 治理目标 OKR)
其二,水位风险的发生可预测,且要有
阶梯预警与响应机制
资源用量的增长有其规律性,这使得水位上升量是可预测的。平台可以早于风险真正发生,就提前发布预警。同时,预警需要与阶梯性的响应机制挂钩,确保预警发出后,确实有人介入处理。
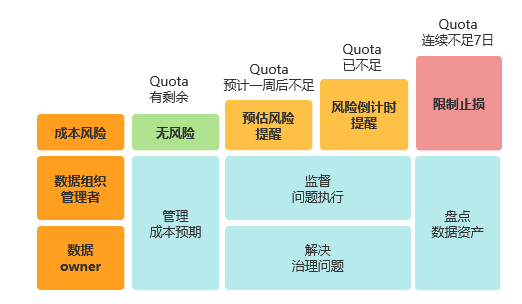
(图十九 治理预警机制)
其三,每个阶段的治理目标和策略,
有组织能快速自上而下传达
以往,数据平台与业务部门的治理沟通,是通过部门老板指派对接人。这种模式下,同一策略反复宣讲、意见调和的沟通成本很高。且由于对接人不承担治理责任、部门组织架构调整带来的人员变动等原因,使得对接人失效率很高。往往只有在事态紧急或者老板明确授权下,才能推进部门治理工作的落实。
22年Q4,B站组建了公司数据委员会,以委员制例会的形式,讨论、颁布大数据治理标准和策略。大数据平台不再对业务部门的治理实施负责,只从公共策略层面掌舵公司的治理实施方向与节奏。相关信息由委员传达到部门内,由委员调配部门内的治理工作。
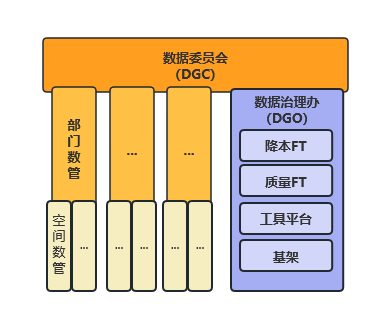
(图二十 数据委员会)
- 截止目前,数据委员会已颁布的标准与策略:
- 成本管理主题,制度标准2项,执行策略3项
- 质量管理主题,制度标准1项,执行策略4项
- 安全管理主题,制度标准1项,执行策略1项
其四,问题的预警和清单,有工具能快速
分发到个人
同样是22年Q4,平台发布了一个可以将治理工作分发到个人的产品——治理中心。治理中心将问题发现、策略解释、危机预警、治理执行、收益统计五大块内容,集成到同一个产品模块,使用户能在一个页面解决散点问题。
建立好以上前置条件,从23年起,B站的大数据资源治理工作形成一个主动性极强的闭环。
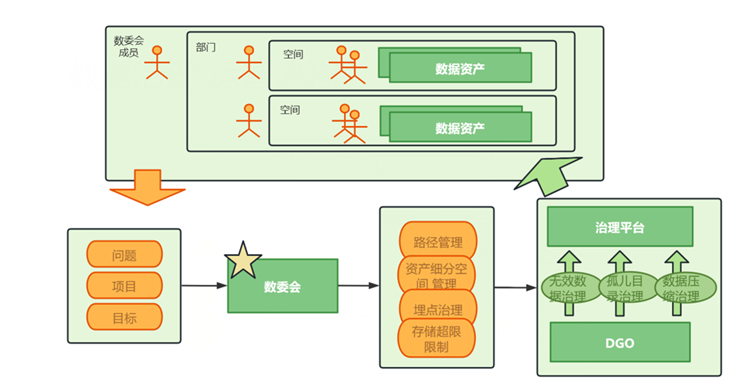
(图二十一 数委会和治理中心组成主动治理闭环)
在这套主动机制建立之前,一次存储高水位应急预案的实施需要数天,并且要平台与业务部门发起紧急临时协调才能将问题解决。该机制下,高水位得以提前预测,无须平台拉起沟通,业务部门响应人员自行介入处理。伴随着主动性提高,存储水位由前两年长期盘踞在 90%,下降至稳定在 75% 左右。
问题二:如何化单点为多元?
前文中提到,主动治理需要在各项资源的问题爆发前,预备好数据和策略。但只是照本宣科地做数据和策略,无法真正实现多元化治理。
多元化治理的核心矛盾点,在资源类型的多元化与人力工时的恒定不变之间。因此,如何提高人效,是实现多元化的关键。为提高人效,我们定义了一个治理操作框架。该框架,确保数据输出是为治理应用服务,确保上一个治理项的发布与实施,能为下一个治理项积累经验、沉淀工具。
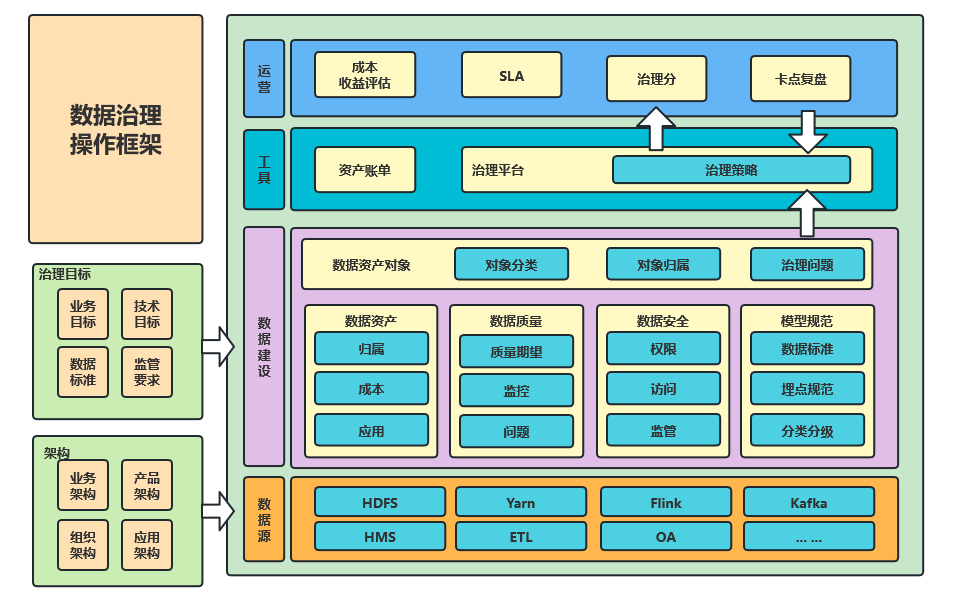
(图二十二 完整治理架构)
其一,平台运营人效
当公司有了主动治理闭环,平台人员的精力,更多放在标准和策略上。运营提效的重点在于靠三个统一来提升标准制定和策略探索的效率。
- 统一的标签模型
为了治理项能快速发布和迭代,我们基于资产元数据构建了资产对象的指标字典和标签字典。例如成本治理中,原本成百上千的治理指标,被合并归纳成7个资产对象, 23个业务过程,160个标签。通过标签组合匹配的形式,治理策略的探索变成一项简单事务,即便一些新人也可快速上手输出有效的治理清单。
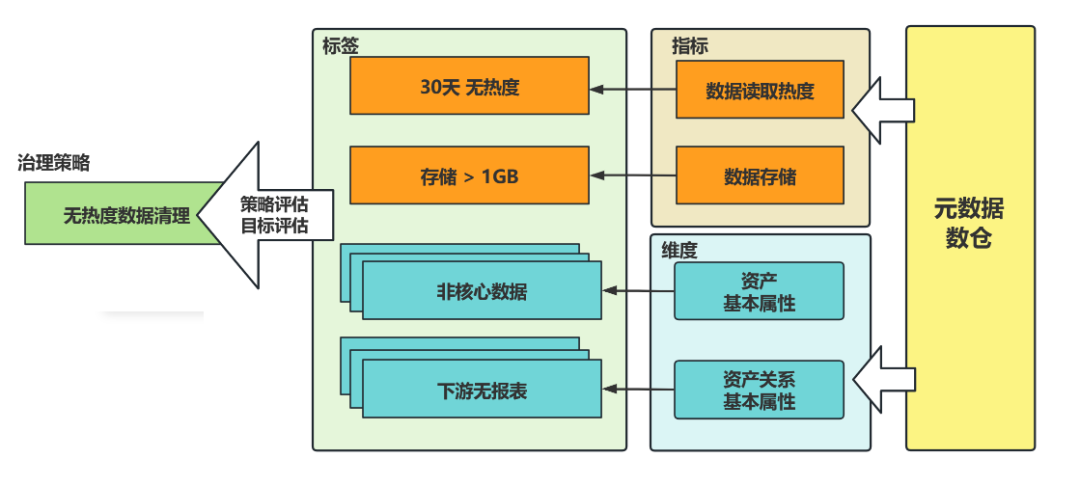
(图二十三 治理标签)
- 统一的管控策略
QUOTA限制,是公司数据委员会上发布过的重磅管控策略之一。它起于存储QUOTA,规定了业务部门的存储用量达到该部门存储QUOTA后,将触发大数据资源使用限制,直至用量恢复到QUOTA以下。
23年多元化治理启动后,QUOTA限制策略陆续将在离线计算、实时计算、传输流量等资源项上实施。同一套方案,多处实施,每一项资源只要明确QUOTA值与用量口径,管控机制就可迅速上线。
同时,平台也支持将这一策略分层实施,即公司层面对部门限制,部门层面对下属工作空间限制。不仅是平台运营人力得到释放,业务部门的数据委员也因此受益。
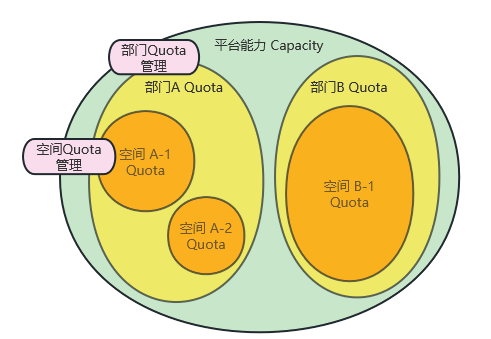
(图二十四 治理配额设计)
- 统一的策略实施流程
资源治理的实施经常是一些销毁操作,而销毁操作需要慎之又慎。为了兼顾快速与谨慎,平台对销毁操作制定了从消费任务到生产任务倒序关闭、每个步骤都可快速回滚的标准流程。该流程可使平台并行铺开多个批次的销毁,又确保每个批次有足够的时间观察销毁影响。
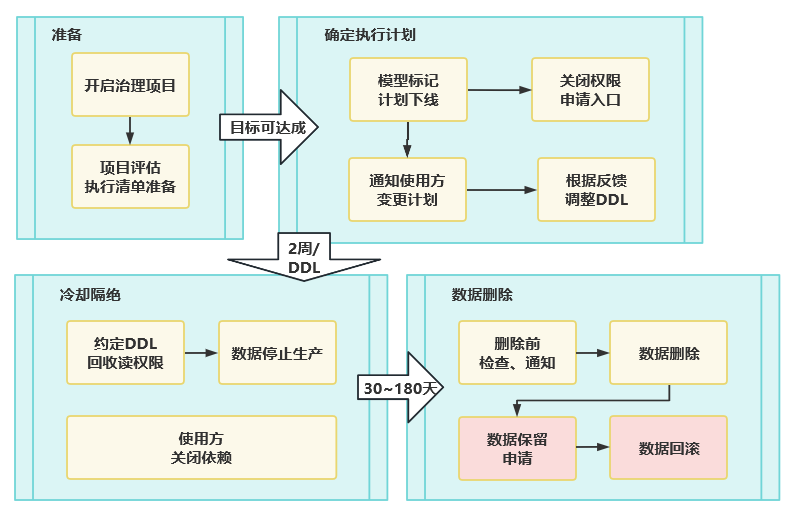
(图二十五 治理实施流程:平台定义SOP)
其二,用户实施人效
用户单位时间治理效果的提升,可以通过降低实施耗时、提升实施收益来实现。
- 自动化工具沉淀,降低工时投入
由于不同资源治理由不同团队推进,发布清单和操作工具不同,用户需要面对多个沟通群,理解背景、获取清单、学习如何处理的成本也很大。治理中心上线后,用户的治理流程被抽象为接收治理中心的推送,通过推送信息进入问题清单,在问题清单进入对应操作模块,操作完回到治理中心查看效果,这样简单的操作框架。
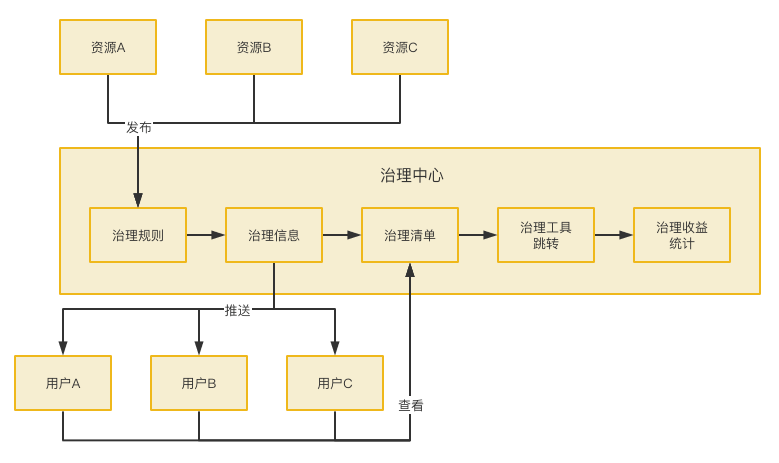
(图二十六 治理实施流程:用户的工具操作流程)
同时,治理工具帮助用户组织、排序清单,收益的顺序、执行前后依赖的顺序等,让用户避免“对无热度表实施压缩”这样的无效劳动。
- 引擎、存储的新技术引入,加大治理收益
22年间,大数据平台先后引入了EC、Z-ORDER等新技术,且由于其对生产链路近乎无损的实施方案,用户只需简单配置,甚至无需配置,即可实现存储资源与计算资源的治理收益。
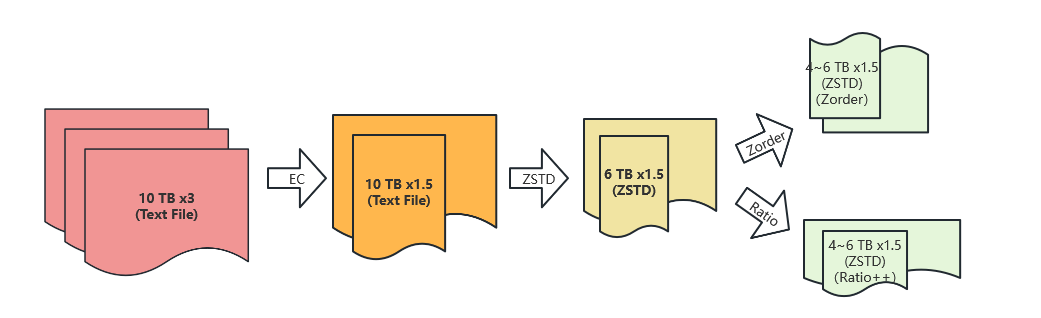
(图二十七 治理新技术 压缩、冷备技术)
蜕变后的新目标
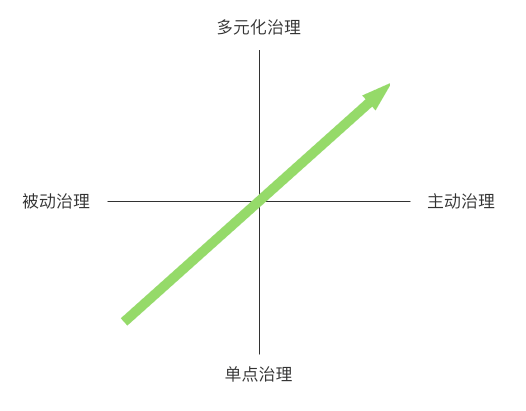
(图二十八 治理长期目标方向)
通过从被动到主动,从单点到多元的演进,我们对23年的大数据资源治理目标也有了新的展望。
- 存储方面,将继续保持安全水位,做到以全年资源成本0增长来支持业务的增长。
- 计算方面,将继存储之后上线QUOTA管控策略,从离线计算、实时计算双线出击,释放异常任务占用的资源,提升单位成本的任务密度。
- 流量方面,将同样上线QUOTA管控策略,流量用量纳入账单分摊,打退埋点成本的上升势头。
后续规划
最后,经过数据治理这1年多工作总结和复盘,我们也规划后续三个核心重点方向。
从成本关注转为成本-价值关注
这个阶段,平台方仅关注资产项的成本,该资产项的业务价值,是由用户主观提供的。后续,平台会设计数据价值评估体系,以更客观的方式描述数据价值,提升大数据资源的ROI。
从碎片治理到集成治理,持续拓展治理
中心的集成能力
治理中心的问题拦截、发现、预警能力,和治理实施操作引导,将持续覆盖到所有大数据资产项、更多问题策略,提升治理运营效率。
引入新技术,优化数据生产、
输出链路
大数据平台正在积极引入湖仓一体、oneservice(统一数据服务)等业内先进方案,旨在:
- 提升单个生产链路的多场景复用性。
- 提升数据、指标产出的多应用复用性。
B站的价值观 中有这样两条 社区优先、合作共赢,感谢 和B站各部门的伙伴们一起走上了这条大数据之路,期待咱们数委会的下一篇《B站大数据治理之路 2.0》!
作者
吴剑雄:哔哩哔哩技术专家
蔡梦苑:哔哩哔哩资深开发工程师
高隆:哔哩哔哩资深开发工程师
本文来源 微信公众号:哔哩哔哩技术