

导读:本文转载自网信上海微信公众号。为数据分类分级、制定重要数据目录试点的优秀成果,分享给大家参考!
一、引言
为加快建立健全数据分类分级保护制度及重要数据目录管理机制,促进数据共享应用,2022年7月至12月,市委网信办会同市政府办公厅成立试点工作组,组织开展了数据分类分级、制定重要数据目录试点工作,遴选出一批试点优秀单位和试点优秀案例。今天分享静安区政府办公室、区委网信办、区政务数据管理中心试点优秀案例——《静安区公共数据分类分级导则》。
二、案例概述
本案例围绕数据分类分级规则、重要数据识别规则、数据分级保护体系,从静安区公共数据分类分级方法及流程、重要数据识别规则、不同生命周期公共数据分级安全保护要求等方面,阐述静安区“1+N”模式的数据分类分级保护制度体系,对数据分类分级及安全管控工作具有参考意义。
案例展示静安区公共数据分类分级导则(节选)
1、范围本导则给出了公共数据分类分级的原则、框架和方法等。本导则适用于指导静安区公共数据分类分级。
2、数据分类分级基本原则
数据分类分级的基本原则为科学实用原则、边界清晰原则、就高从严原则、点面结合原则、动态更新原则
3、数据分类方法
1)数据分类框架
本导则采用点面结合的形式。常见的数据分类维度,包括但不限于公民个人维度、公共管理维度、信息传播维度、组织经营维度。
数据处理者可采用点面结合的方式对数据进行分类,在遵循国家和行业数据分类要求的基础上,对不同维度的数据类别进行标识,再进一步细分每个维度的数据类型。
2)用户数据分类
a)个人信息分类按照涉及的自然人特征,个人信息可分为个人基本资料、个人身份信息等二十一个类别。
b)组织信息分类组织信息分类可根据组织架构实际情况,对组织信息进行细化分类。
c)业务数据分类业务数据分类可根据各部门业务具体情况,对业务数据进行细化分类。
d)管理数据分类管理数据分类可根据各部门实际管理情况,对管理数据进行细化分类。
e)监管数据分类监管数据分类可根据各监管部门实际监管情况,对监管数据进行细化分类。
4、数据分级方法
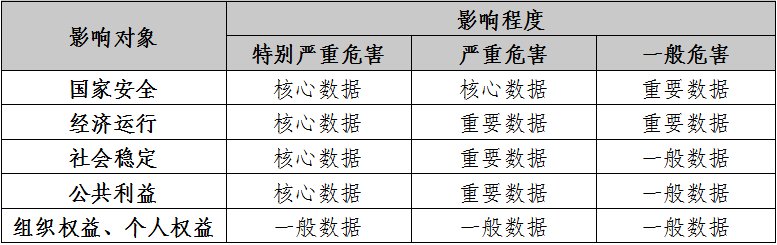
数据分级主要是从数据安全保护的角度,考虑影响对象、影响程度两个要素进行分级。数据分级为核心数据、重要数据、一般数据(1级、2级、3级、4级)。
资源目录数据分级是指区数据责任部门在公共数据库表目录基础上定期、按需梳理和编制全量公共数据资源目录,评估公共数据资源目录中所编数据的潜在影响,定义公共数据资源目录中的数据集及其数据项的安全级别,并对其安全分级进行评审,提交区公共数据主管部门审核。若有属于国家核心数据或重要数据目录的,还应上报市有关部门备案。
1)影响对象影响对象是指数据一旦遭到泄露、篡改、破坏或者非法获取、非法利用、非法共享,可能影响的对象。影响对象通常包括国家安全、经济运行、社会稳定、公共利益、组织权益、个人权益等。
2)影响程度影响程度是指数据一旦遭到泄露、篡改、破坏或者非法获取、非法利用、非法共享,可能造成的影响程度。影响程度从高到低可分为特别严重危害、严重危害、一般危害。
3)基本分级原则影响对象、影响程度与数据级别的关系如表1所示。在分级要素识别、数据影响分析的基础上,可参考以下规则确定数据级别。
a)核心数据为对领域、群体、区域具有较高覆盖度或达到较高精度、较大规模、一定深度的重要数据,一旦被非法使用或共享,可能直接影响政治安全。满足以下任一条件的数据,可考虑确定为核心数据:
i.数据一旦被泄露、篡改、损毁或者非法获取、非法使用、非法共享,可能直接对国家安全造成特别严重危害(如直接影响政治安全)或严重危害(如关系国家安全重点领域);
ii.数据一旦被泄露、篡改、损毁或者非法获取、非法使用、非法共享,可能直接对经济运行造成特别严重危害(如关系国民经济命脉);
iii.数据一旦被泄露、篡改、损毁或者非法获取、非法使用、非法共享,可能直接对社会稳定造成特别严重危害(如关系重要民生);
iv.数据一旦被泄露、篡改、损毁或者非法获取、非法使用、非法共享,可能直接对公共利益造成特别严重危害(如关系重大公共利益);
v.对领域、群体或区域具有较高覆盖度,可能直接影响政治安全、国家安全重点领域、国民经济命脉、重要民生、重大公共利益的重要数据;
vi.达到较高精度、较大规模或一定深度,可能直接影响政治安全、国家安全重点领域、国民经济命脉、重要民生、重大公共利益的重要数据;vii.经有关部门评估确定的核心数据。
b)重要数据为特定领域、特定群体、特定区域或达到一定精度和规模的数据,一旦被泄露或篡改、损毁,可能直接危害国家安全、经济运行、社会稳定、公共健康和安全。满足以下任一条件的数据,可考虑确定为重要数据:
i.数据一旦被泄露、篡改、损毁或者非法获取、非法使用、非法共享,可能直接对国家安全造成一般危害;
ii.数据一旦被泄露、篡改、损毁或者非法获取、非法使用、非法共享,可能直接对经济运行造成严重危害或一般危害;
iii.数据一旦被泄露、篡改、损毁或者非法获取、非法使用、非法共享,可能直接对社会稳定造成严重危害;
iv.数据一旦被泄露、篡改、损毁或者非法获取、非法使用、非法共享,可能直接对公共利益造成严重危害(如危害公共健康和安全);v.数据直接关系国家安全、经济运行、社会稳定、公共健康和安全的特定领域、特定群体或特定区域;
vi.数据达到一定精度、规模或深度,可能直接影响国家安全、经济运行、社会稳定、公共健康和安全;
vii.经行业领域主管(监管)部门评估确定的重要数据。c)满足以下任一条件的数据,可定级为一般数据:
i.数据一旦遭到篡改、破坏、泄露或者非法获取、非法利用、非法共享,仅可能对社会稳定造成一般危害;
ii.数据一旦遭到篡改、破坏、泄露或者非法获取、非法利用、非法共享,仅可能对公共利益造成一般危害;
iii.数据一旦遭到篡改、破坏、泄露或者非法获取、非法利用、非法共享,仅影响组织合法权益;
iv.数据一旦遭到篡改、破坏、泄露或者非法获取、非法利用、非法共享,仅影响公民合法权益;
v.经国家有关部门、各行业各领域主管(监管)部门和各地区、各部门等评估,均未被确定为核心数据和重要数据的数据。
表1 数据分级参考规则
4)一般数据分级原则按照数据一旦遭到篡改、破坏、泄露或者非法获取、非法利用,对个人、组织合法权益造成的危害程度,将一般数据从高到低分为四级、三级、二级、一级。
注:针对一般数据中的个人敏感信息,若个人敏感信息涉及10万人以上则将数据提级为重要数据;针对一般数据中的个人信息涉及100万人以上,则将数据提级为重要数据。
5)一般数据最低参考级别一般数据分级考虑敏感个人信息等特定类型数据的敏感性,特定类型数据最低参考级别包括:
a)敏感个人信息不低于“四级”,一般个人信息不低于“二级”;
b)组织内部员工个人信息不低于“二级”;
c)去标识化的个人信息不低于“二级”,匿名化个人信息不低于“一级”;
d)个人标签信息不低于“二级”;
e)有条件开放/共享的公共数据级别不低于“二级”,禁止开放/共享的公共数据或政务数据不低于“四级”。
6)衍生数据安全参考级别衍生数据安全级别可参考其所对应的原始数据集级别,综合考虑数据加工对分级要素、影响对象、影响程度的影响:
a)脱敏数据级别可以比原始数据集级别降低;
b)标签数据级别可以比原始数据集级别降低;
c)统计数据如涉及大规模群体特征或行动轨迹,应设置比原始数据集级别更高的级别;
d)融合数据级别要考虑数据汇聚融合结果,如果结果数据是对大量多维数据进行关联、分析或挖掘,汇聚了更大规模的原始数据或分析挖掘出更敏感、更深层的数据,级别可以升高,但如果结果数据降低了标识化程度等,级别可以降低。
7)重要数据识别规则识别重要数据遵循的原则如下:
a)聚焦安全影响:从国家安全、经济运行、社会稳定、公共健康和安全等角度识别重要数据,仅影响组织自身或公民个体的数据一般不作为重要数据,但要考虑对海量数据挖掘分析的结果;
b)突出保护重点:通过对数据分级,明确重点保护对象,使重要数据在满足安全保护要求前提下有序流动;
c)衔接既有规定:充分考虑地方已有管理要求和行业特性,与地方、部门已经制定实施的有关数据管理政策和标准规范紧密衔接;
d)综合考虑风险:根据数据所在领域、覆盖群体、用途、面临威胁等不同因素,综合考虑数据遭到篡改、破坏、丢失、泄露或者非法获取、非法利用等风险,从保密性、完整性、可用性、真实性、准确性等多个角度分析判断数据的重要性;
e)定量定性结合:以定量与定性相结合的方式识别重要数据,并根据具体数据类型、特性不同采定量或定性方法;
f)动态识别复评:随着数据用途、共享方式、重要性等发生变化,动态识别重要数据,并定期复查重要数据识别结果。具体重要数据目录示例见配套文件。
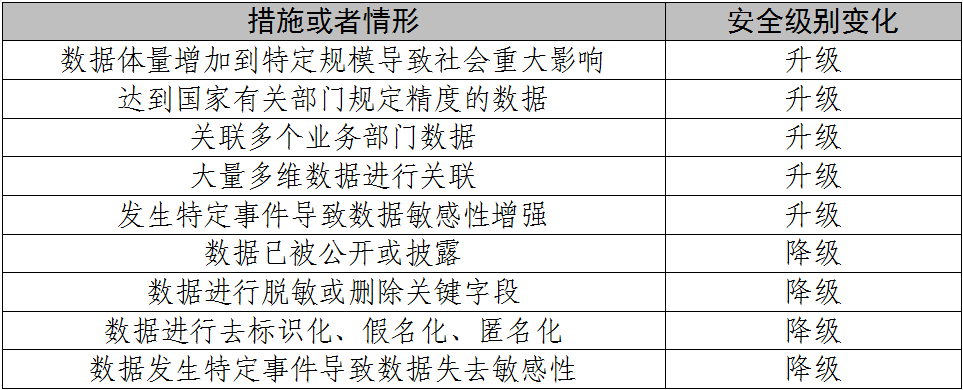
8)数据重新定级数据安全定级完成后,出现下列情形之一时,应重新定级:
a)数据内容发生变化,导致原有数据的安全级别不再适用;
b)数据内容未发生变化,但数据时效性、数据规模、数据应用场景、数据加工处理方式等发生变化;
c)多个原始数据直接合并,导致原有的安全级别不再适用合并后的数据;
d)因对不同数据选取部分数据进行合并形成的新数据,导致原有数据的安全级别不再适用合并后的数据;
e)不同数据类型经汇聚融合形成新的数据类别,导致原有的数据级别不再适用于汇聚融合后的数据;
f)因国家或行业主管部门要求,导致原定的数据级别不再适用;
g)需要对数据安全级别进行变更的其他情形。
表2 数据安全级别变化示例表
9)常见数据定级参考因素
领域:是指数据描述的业务范畴,数据领域识别可考虑数据描述的行业领域、业务条线、生产经营活动、上下游环节、内容主题等因素。
群体:是指数据描述的主体或对象集合,数据群体识别可考虑数据描述的特定人群、特定组织、网络和信息系统、资源物资、设备设施等因素。
区域:是指数据涉及的地区范围,数据区域识别可考虑数据描述的行政区划、特定地区、物理场所等。
精度:是指数据的精确或准确程度,数据精度越高表示采集数据和真实数据的误差越小。数据精度识别可考虑数值精度、空间精度、时间精度等因素。
规模:是指数据规模及数据描述的对象范围或能力大小,数据规模识别可考虑数据存储量、群体规模、区域规模、领域规模、生产加工能力等因素。
深度:是指通过数据统计、关联、挖掘或融合等加工处理,对数据描述对象的隐含信息或多维度细节信息的刻画程度。数据深度识别可考虑数据在刻画描述对象的经济运行、发展态势、行踪轨迹、活动记录、对象关系、历史背景、产业供应链等方面的情况。
覆盖度:是指数据对领域、群体、区域、时段等的覆盖分布或疏密程度。数据覆盖度识别可考虑对特定领域、特定群体、特定区域、时间段的覆盖占比、覆盖分布等因素。
重要性:是指数据在经济社会发展中的重要程度。重要性识别可考虑数据在经济建设、社会建设、政治建设、文化建设、生态文明建设等的重要程度。
安全风险:主要识别数据可能遭到泄露、篡改、破坏、非法获取、非法利用、非法共享的风险。
5、数据分类分级流程数据分类分级流程见图1。
图1 数据分类分级流程
6、数据分级安全保护要求
数据安全保护应依据本导则,根据数据级别采取相应的管理措施和技术手段对数据采集、汇聚、传输、存储、加工、共享、开放、使用等环节进行有针对性的保护,个人信息、敏感数据和重要数据要加强安全管控措施,核心数据应采取更加严格的管控措施。数据安全保护要求分为通用要求、技术要求和管理要求三部分。
通用要求从系统安全、身份认证、授权访问、访问控制、数据标识、安全审计、监测溯源七方面对不同级别的数据规定了概括性、整体性的数据安全保护要求。
技术要求针对数据的全生命周期对不同级别的数据规定了数据处理活动的安全保护技术要求。
管理要求从安全策略、安全机构、安全人员、安全审核、分级管理、检查和考核、安全评估、应急处置、安全监管九方面规定了数据安全相关的组织机构、人员以及活动的安全保护管理要求。