

导读 数据作为新生产要素,是企业的重要资产,对数据全生命周期管理对企业数据应用、数据安全、用户隐私保护等都具有重要作用。本文将介绍爱奇艺在数据链路治理方面的实践和探索,包括通过离线链路治理保证数据准确性和时效性,通过实时链路治理快速定位异常数据,以及目前爱奇艺在链路治理中开展的数据智能归因、字段血缘等探索性工作。
全文目录:
1. 问题和目标
2. 离线链路治理
3. 实时链路治理
4. 探索
01问题和目标
首先分享一下爱奇艺在数据管理过程中进行数据链路治理的原因和目标。
1. 问题
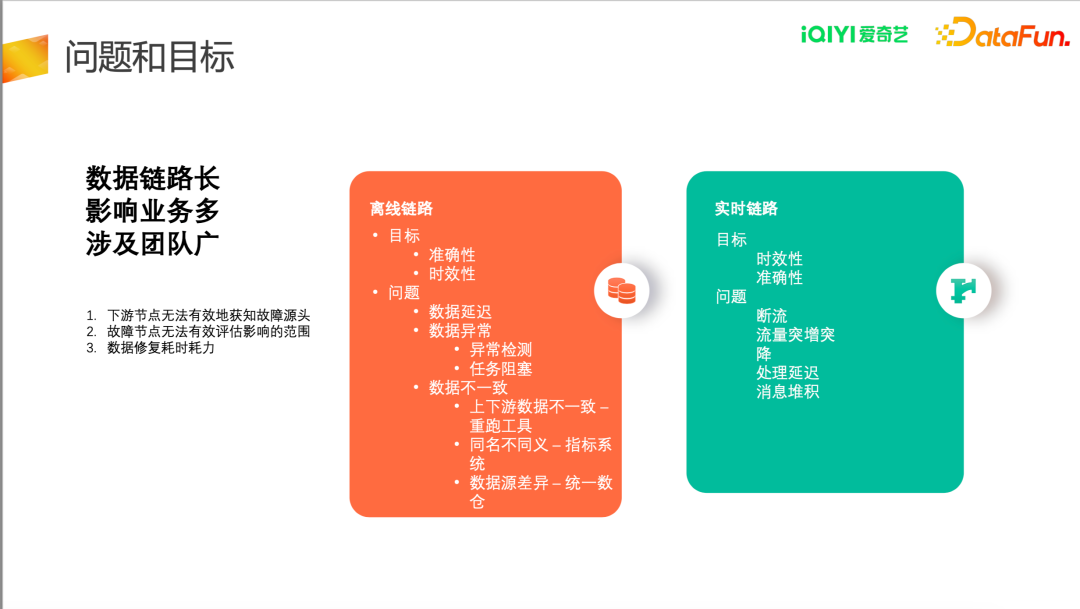
驱动爱奇艺开展数据链路治理工作的原因主要有以下几方面:
- 爱奇艺相关生产运营工作中,数据的获取、加工、下发等流程中会涉及很多数据,来自不同的业务线、不同的业务集市的,整个数据链路很长;
- 一旦数据出现问题,影响的业务非常多;
- 数据异常影响的团队广,这其中既涉及底层的数仓团队,也会涉及上层的各个业务团队。
我们遇到的问题包括:
- 下游节点无法有效获知故障源头;
- 故障节点无法有效评估影响范围;
- 数据修复耗时耗力,一个故障可能会涉及多个团队,相应协调工作很多。
2.治理链路
爱奇艺的数据链路治理包括离线链路和实时链路两部分,两者针对的问题和目标有部分差异。
(1)离线链路
离线链路治理的目标是:
- 准确性:优先保障数据的准确性和可用性;
- 时效性:要保证数据在约定的时间之前产出。
离线数据常见的问题包括:
- 数据延迟:由于集群故障或者任务执行问题,数据出现延迟,严重的情况下会导致滚雪球现象,前序数据延迟会导致后续节点依次延迟。
- 数据异常:数据出现缺失或者大的表动导致报表计算不准确,爱奇艺内部针对数据异常接入了数据质量检测并对任务进行及时阻断,防止对下游造成更大影响。
- 数据不一致:上下游数据不一致,如上游某些数据重跑,未及时通知下游,造成数据不一致的情况,爱奇艺目前使用了重跑工具,在上游进行数据重跑时,会把消息发给下游;同名不同义问题,如同一个字段,在不同的表里可能有不同的含义,用户使用中会产生歧义,这一点在早期粗放开发中是比较常见的问题,目前爱奇艺使用指标系统,对所有指标给定唯一定义,相关指标上线修改等需进行审核;数据源差异,通过统一数仓管理底层数据输出。
(2)实时链路
实时链路治理的目标是:
- 时效性:实时数据对时效性的要求更高;
- 准确性:数据是准确性高的、高可用的。
实时数据常见的问题包括:
- 断流;
- 流量突增突降;
- 处理延迟;
- 消息堆积。
接下来将分别介绍离线链路和实时链路的治理。
02 离线链路治理
离线链路治理主要分四个方面。
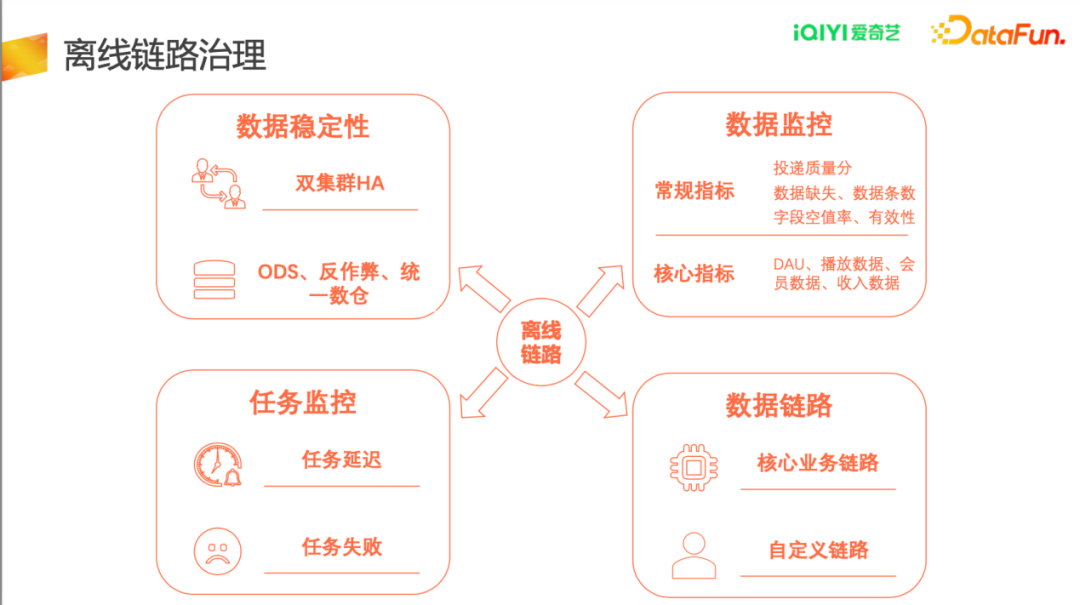
- 数据稳定性:对重要的数据节点,包括ODS层、反作弊层、统一数仓等进行双集群HA处理,保证数据稳定产出;
- 任务监控:包括任务延迟监控和任务失败监控;
- 数据监控:爱奇艺数据监控覆盖了从源头到上层报表的所有数据环节,包括在Pingback层,对核心事件的核心字段对其数据缺失、数据条数、字段空值率及有效性进行了日常监控,同时引入了投递质量分,用以评估Pingback的投递质量并推动业务方整改;在中间层和报表层,会对业务核心指标,如DAU、播放数据、会员数据、收入数据等,会重点监控数据的异常变动。
- 数据链路:对重点业务上线数据链路大盘,直观下游报表所依赖的上游数据的血缘关系和完成情况,同时也支持用户自定义链路的监控,关注其中的核心节点运行情况;
下面具体来看每一方面。
1.任务稳定性——双集群HA
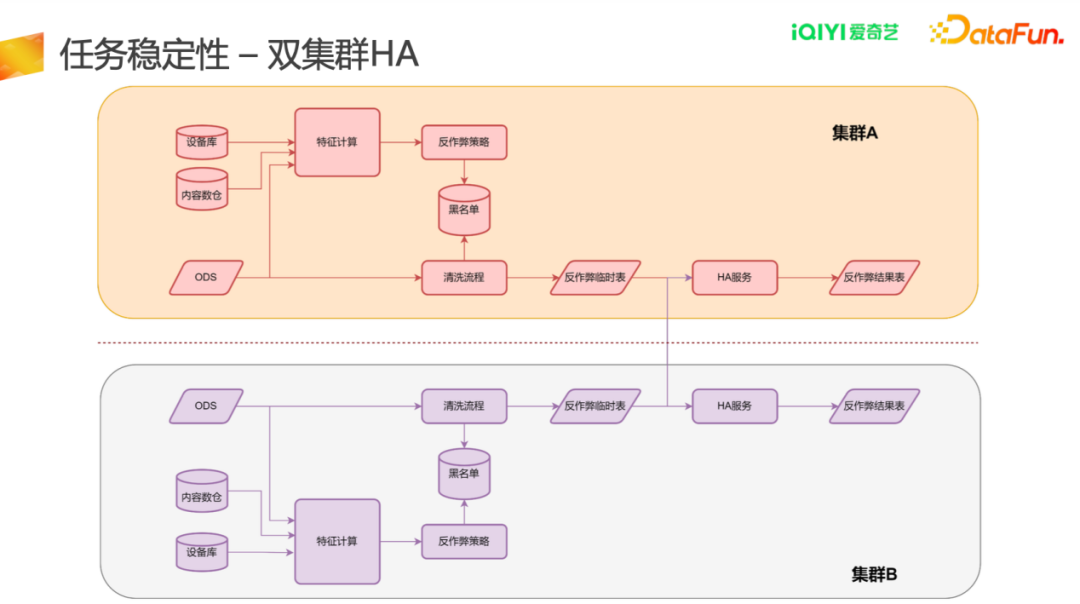
任务稳定性保障方面,爱奇艺内部存在多个集群,每个集群都需要保证数据可用,对于核心业务需要数据保质保量产出。基于此,我们对核心业务均进行了双集群部署,每个集群都会部署独立任务进行处理,在正式产出任务结果之前,会将集群数据写入HA服务(临时表),一般按照哪个集群优先产生结果,另一个集群进行同步的方式进行处理。采用双集群HA部署后,整体数据延迟或数据故障率有了大幅降低。
2.数据监控

数据监控方面,重点是数据指标的监控,包括两部分,一个是投递层Pingback数据,另一个是报表层数据。用户在数据质量平台配置有数据异常检测的规则,平台会对指标数据进行预处理,转换为通用数据格式后,对数据进行异常检测,出现数据异常时会产生相应的工单通知用户处理。为了评估异常检测的有效性,平台会收集用户反馈的样本进行模型训练,用来优化数据质量平台所使用的各类模型。
目前所使用的模型包括阈值检测、相关性分析(对具有强相关性的指标进行分析,如DAU与播放数据具有相关性,若DAU没有明显变化而播放数据出现激增可及时提示异常)、Prophet模型、箱体检测、高斯检测,以及同环比分析等。
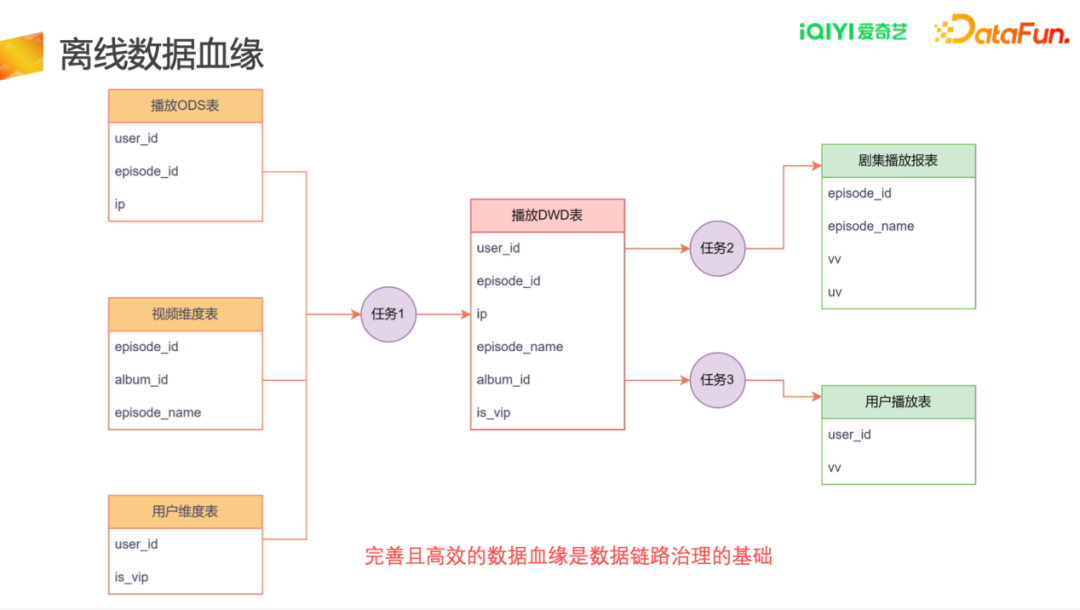
3.离线数据血缘
爱奇艺目前的血缘关系是在表级别和任务级别。每个表都会有一个写入任务,以及一个任务是由哪些表组成的,构成一个完整的血缘关系。通过血缘关系,一方面当下游一个表/任务出现延迟可以定位到具体的上游;另一方面,当中间表出现问题时可以快速分析影响到的下游。通过血缘关系可实现数据重跑和消息通知的自动化。
4.数据链路
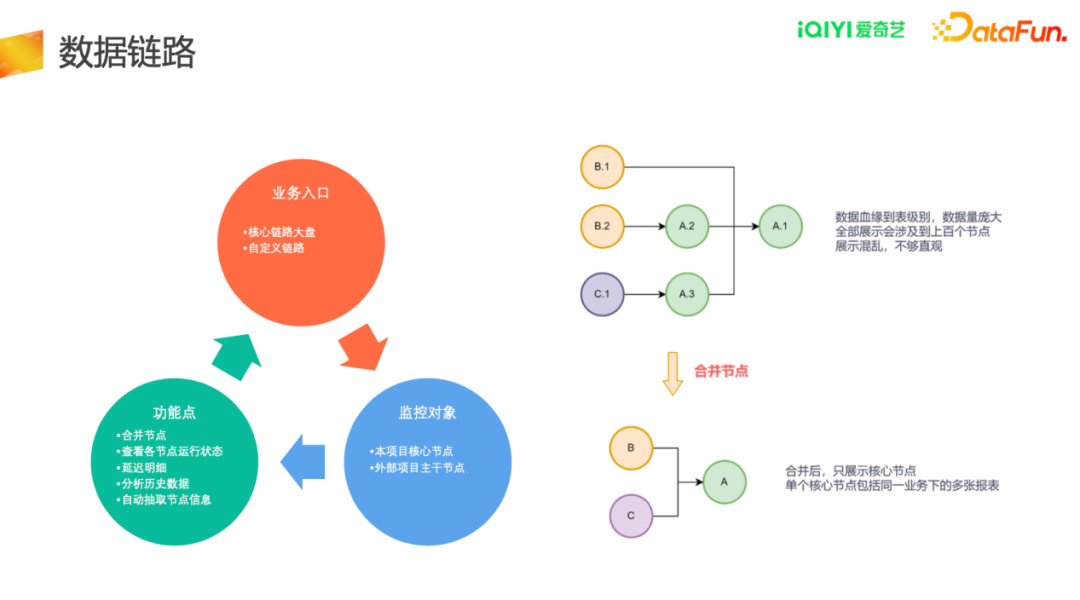
数据链路方面,我们主要关注核心业务链路各节点的运行情况。在实践中,我们从业务入口出发,确定监控对象,对业务所涉及的节点,按业务需求进行节点合并(一个业务往往会涉及上百张报表,这些节点全部展示会造成展示混乱,节点管理困难),通过可视化方式查看节点运行状态,查看延迟明细(双击合并节点可查看明细),分析历史数据并自动抽取节点信息。
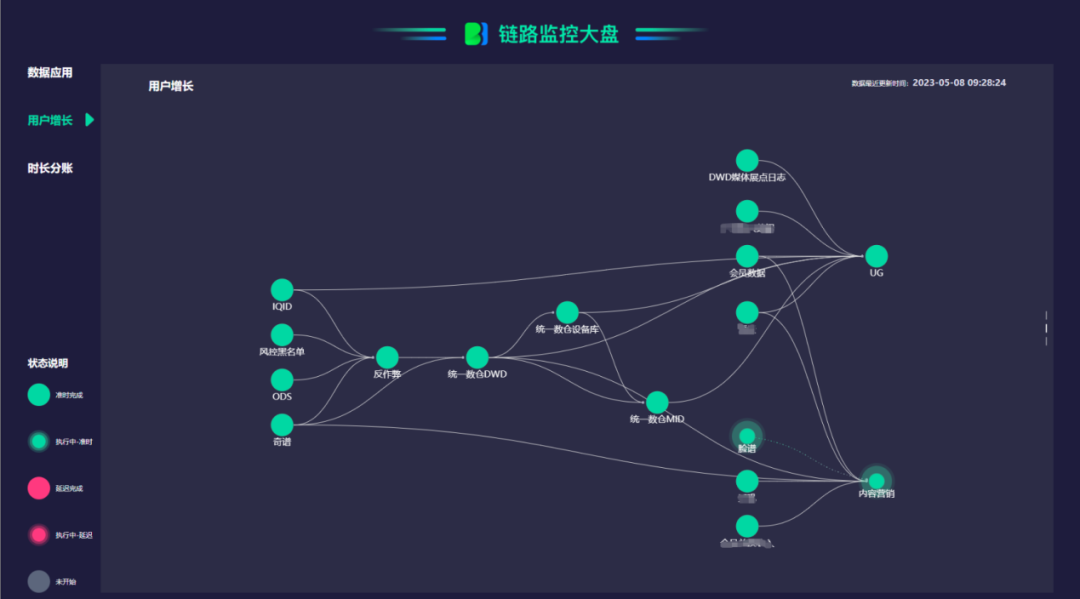
上图是爱奇艺链路监控大盘,目前该大盘主要放了三个业务节点大盘,从用户增长盘来说,通过上图可以直观观测到用户增长所涉及的核心节点及这些节点的运行状态。状态分为五种:绿色代表准时完成;绿色闪烁代表执行中-准时;红色代表延迟完成;红色闪烁代表执行中-延迟;灰色代表未开始。
03 实时链路治理
实时链路治理主要有两大方面。

- 数据稳定性:所有核心业务在实时链路上均部署双集群HA;同时,配有快速切换工具,当某一链路出现问题可快速便捷进行主备切换;
- 实时链路监控:一是流量监控,对断流、突增突降、消费延迟、消息积压、主备流量差异等进行监控;二是业务指标,对反作弊、热度、用户增长等业务进行指标监控(如在营销推广过程中与多个媒体开展合作,整体流量上不会有太大变动,但在业务层可能单个媒体数据已经异常);三是服务监控,在实践中很多业务层问题可能最终会定位到底层服务问题。
1.实时链路监控
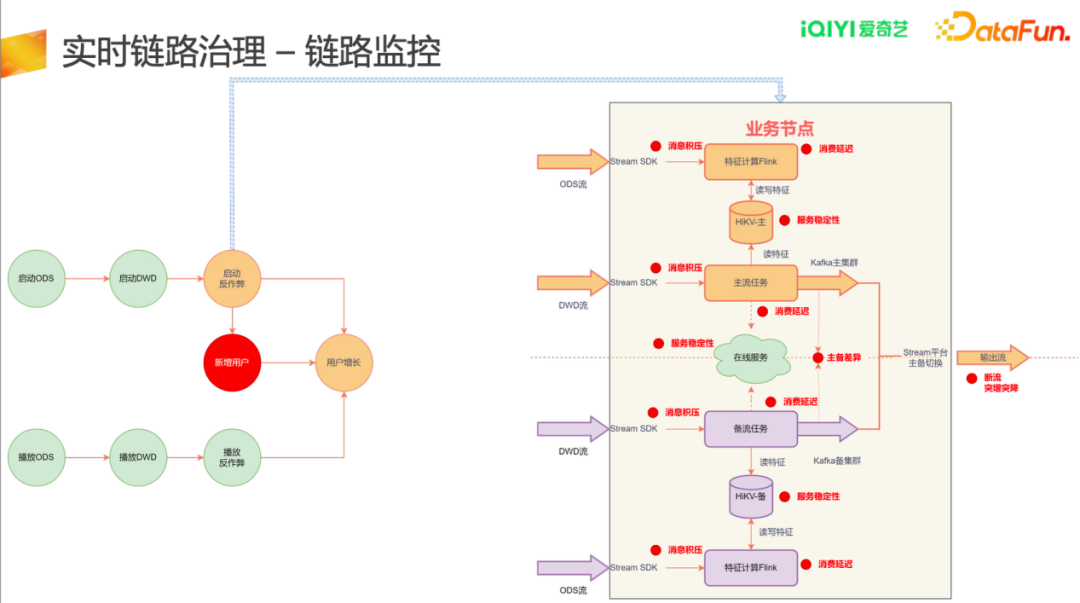
实时链路监控中所有节点都会有主备监控,每个节点所涉及监控内容包括:
- Kafka集群:断流、突增突降监控;
- 主流任务:消息积压、消费延迟;
- 业务层:主备差异监控。
相应监控会以主任务状态作为主要呈现展示在监控大盘中。
2.实时链路大盘
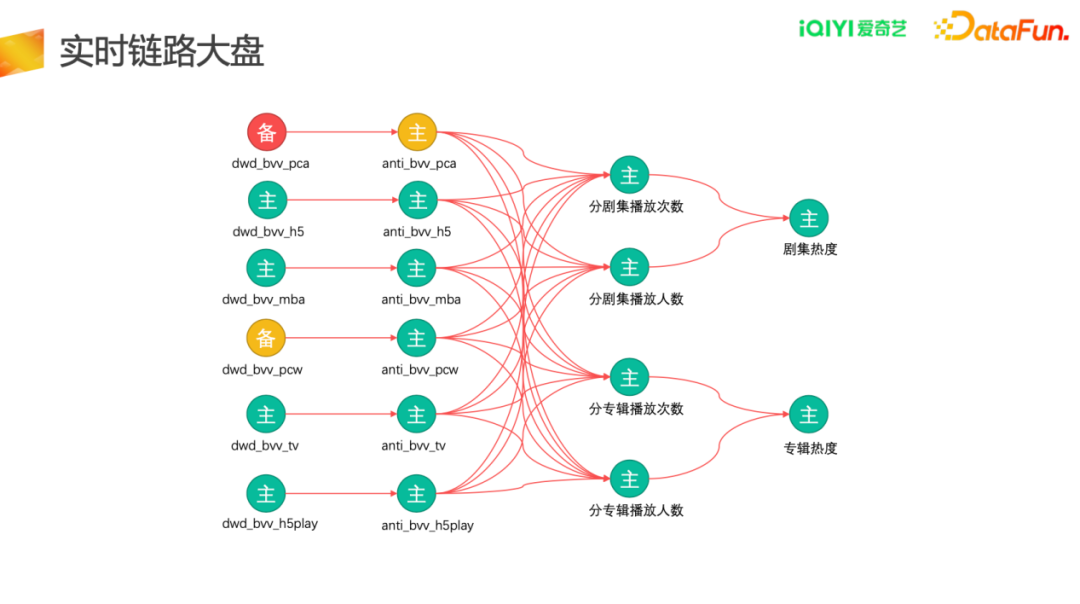
以热度监控大盘为例,主要关注三种监控状态,一是断流和突增突降(红色),这是最严重的异常问题,需要第一优先级处理;二是任务级别监控(黄色),包括消息延迟和消费积压;三是运行正常的状态(绿色)。
04 探索
在前述分享中,我们提到数据治理有几个问题,一个是数据异常检测,这属于发现问题的过程,一般分析问题原因的过程时间可能会比较长,在探索中,我们计划引入智能归因,通过专家系统自动检测异常原因;第二个是字段血缘,精确评估数据对下游的影响范围,目前爱奇艺主要采用表血缘方式来进行评估,实践中会出现评估影响范围扩大化的问题;第三个是流程管控,当出现问题时可以及时阻断任务,自动通知下游,目前这一部分主要通过业务手动配置,实践中仍有一定延迟性。
1.字段血缘
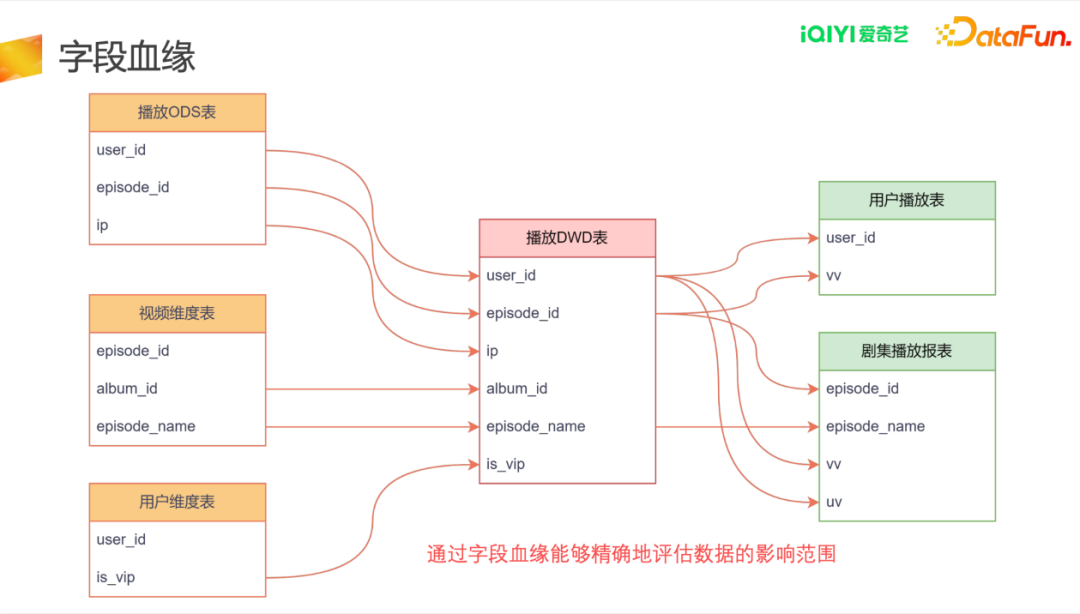
在字段血缘中我们期望可以实现,直观、明确的展示出每个字段使用的是上游表里的哪个字段,下游表中各字段使用的是上游表中的哪些字段,这样可以便于精确评估数据发生问题会影响哪些字段,这些字段对下游的影响有哪些,可以精确通知下游。
2.智能归因
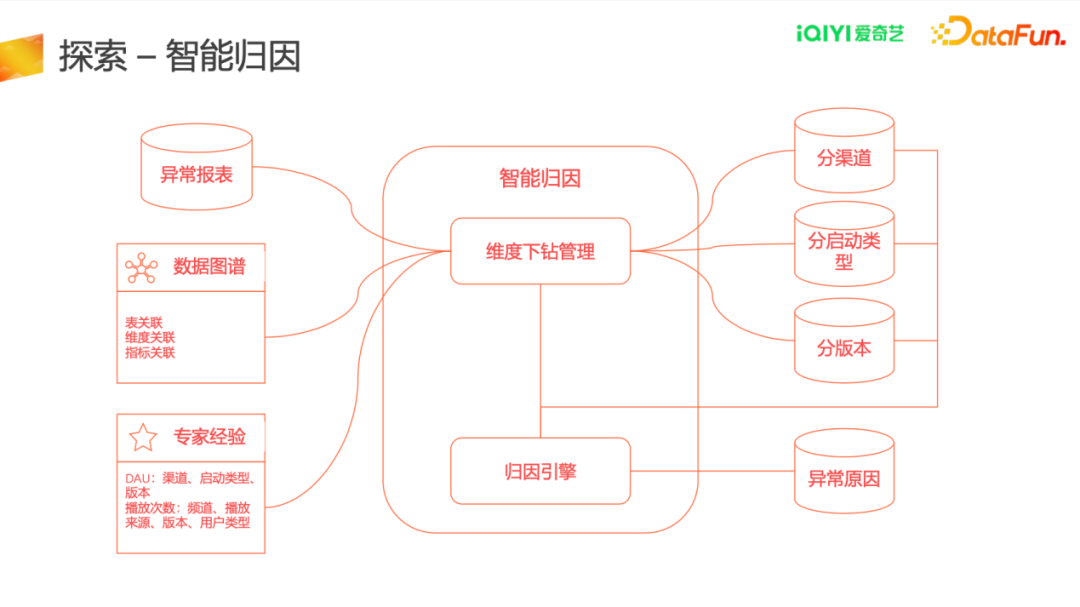
通过接入数据图谱、异常报表、专家经验来分析异常原因。在实践中,我们与数据分析师、产品、运营等团队沟通总结出数据异常的原因有70%以上概率与运营和投递相关,如与渠道投放相关、与版本发布相关;
通过专家经验进行归因下钻,可以将数据异常进行自动化处理,进一步归类到具体的渠道、启动类型或者版本上,及时判断异常产生的原因,减少分析工作量,提高决策效率。
今天的分享就到这里,谢谢大家。
文章来源:“畅谈Fintech”微信公众号