

导读:数据血缘是DMBOK中的一个非常重要概念,多个领域都提到数据血缘。作为一种动态的元数据,管理好血缘也是一个难点,本文介绍了血缘管理实战的经验,值得好好学习。
在复杂的社会分工协作体系中,我们需要明确个人定位,才能更好的发挥价值,数据也是一样,于是,数据血缘应运而生。今天这篇文章会全方位的讲解数据血缘,并且给出具体的落地实施方案。
一、数据血缘是什么
数据血缘是在数据的加工、流转过程产生的数据与数据之间的关系。提供一种探查数据关系的手段,用于跟踪数据流经路径。
二、数据血缘的组成
1、数据节点
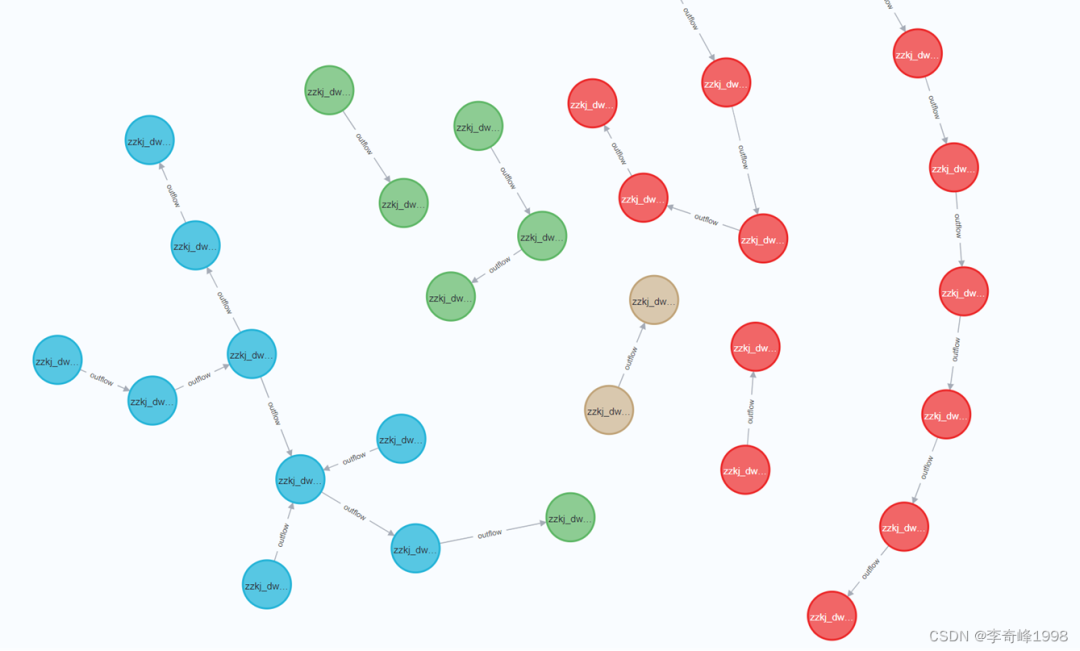
数据血缘中的节点,可以理解为数据流转中的一个个实体,用于承载数据功能业务。例如数据库、数据表、数据字段都是数据节点;从广义上来说,与数据业务相关的实体都可以作为节点纳入血缘图中,例如指标、报表、业务系统等。按照血缘关系划分节点,主要有以下三类:流出节点->中间节点->流入节点
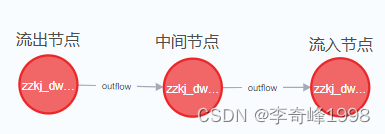
流出节点: 数据提供方,血缘关系的源端节点。
中间节点: 血缘关系中类型最多的节点,既承接流入数据,又对外流出数据。
流入节点: 血缘关系的终端节点,一般为应用层,例如可视化报表、仪表板或业务系统。
2、节点属性
当前节点的属性信息,例如表名,字段名,注释,说明等。
3、流转路径
数据流转路径通过表现数据流动方向、数据更新量级、数据更新频率三个维度的信息,标明了数据的流入流出信息:
数据流动方向: 通过箭头的方式表明数据流动方向。
数据更新量级: 数据更新的量级越大,血缘线条越粗,说明数据的重要性越高。
数据更新频率: 数据更新的频率越高,血缘线条越短,变化越频繁,重要性越高。
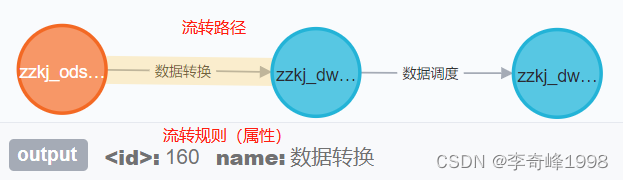
4、流转规则-属性
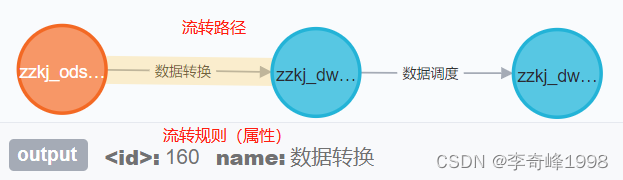
流转规则体现了数据流转过程中发生的变化,属性则记录了当前路径对数据的操作内容,用户可通过流转路径查看该路径规则与属性,规则可以是直接映射关系,也可以是复杂的规则,例如:数据映射: 不对数据做任何变动,直接抽取。数据清洗: 表现数据流转过程中的筛选标准。例如要求数据不能为空值、符合特定格式等。数据转换: 数据流转过程中,流出实体的数据需要进行特殊处理才能接入到数据需求方。数据调度: 体现当前数据的调度依赖关系。数据应用: 为报表与应用提供数据。
三、我们为什么需要数据血缘
1、日益庞大的数据开发导致表间关系混乱,管理成本与使用成本激增
数据血缘产生最本质的需求。大数据开发作为数据汇集与数据服务提供方,庞大的数据与混乱的数据依赖导致管理成本与使用成本飙升。
2、数据价值评估,数据质量难以推进
表的优先级划分,计算资源的倾斜,表级数据质量监控,如何制定一个明确且科学的标准。
3、什么表该删,什么表不能删,下架无依据
业务库,数仓库,中间库,开发库,测试库等众多库表,是否存在数据冗余(一定存在)。以及存储资源如何释放?
4、动了一张表,错了一堆表
你改了一张表的字段,第二天醒来发现邮件里一堆任务异常告警。
5、ETL任务异常时的归因分析、影响分析、恢复
承接上个问题,如果存在任务异常或者ETL故障,我们如何定位异常原因,并且进行影响分析,以及下游受影响节点的快速恢复。
6、调度依赖混乱
数据依赖混乱必然会带来调度任务的依赖混乱,如何构建一个健壮的调度依赖。
7、数据安全审计难以开展针对银行、保险、政府等对安全关注度较高的行业,数据安全-数据泄露-数据合规性需要重点关注。由于数据存在ETL链路操作,下游表的数据来源于上游表,所以需要基于数据全链路来进行安全审计,否则可能会出现下游数据安全等级较低,导致上游部分核心数据泄露。
四、数据血缘可以做什么
1、流程定位,追踪溯源
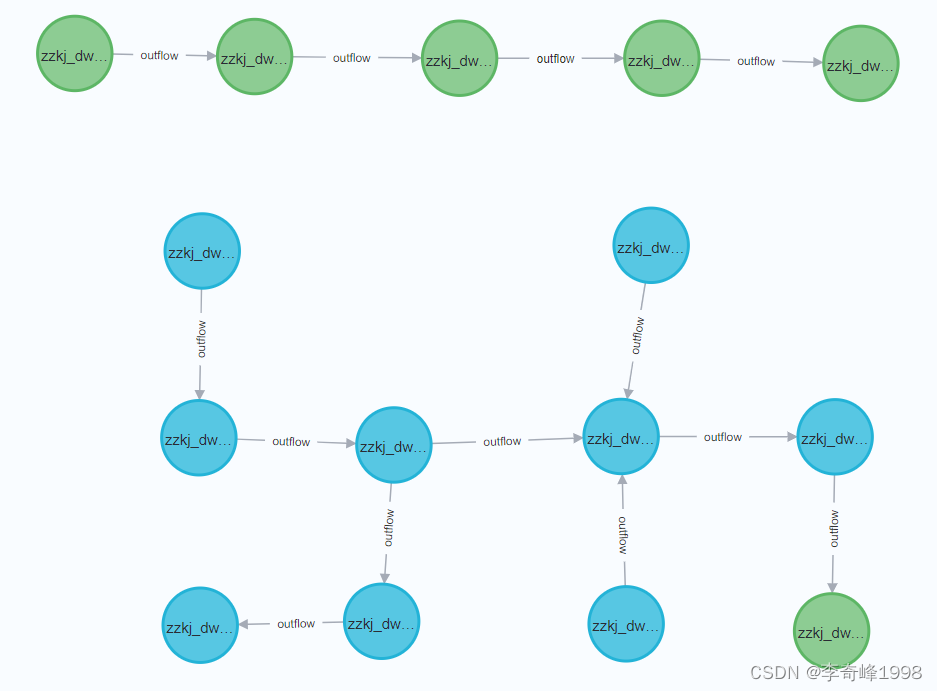
通过可视化方式,将目标表的上下游依赖进行展示,一目了然。
2、确定影响范围
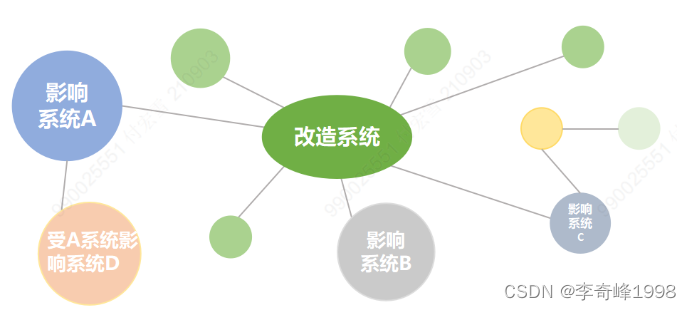
通过当前节点的下游节点数量以及类型可以确定其影响范围,可避免出现上游表的修改导致下游表的报错。
3、评估数据价值、推动数据质量
通过对所有表节点的下游节点进行汇总,排序,作为数据评估依据,可重点关注输出数量较多的数据节点,并添加数据质量监控。
4、提供数据下架依据
例如以下数据节点,无任何下游输出节点,且并无任何存档需求,则可以考虑将其下架删除。

5、归因分析,快速恢复
当某个任务出现问题时,通过查看血缘上游的节点,排查出造成问题的根因是什么。同时根据当前任务节点的下游节点进行任务的快速恢复。
6、梳理调度依赖
可以将血缘节点与调度节点绑定,通过血缘依赖进行ETL调度。
7、数据安全审计
数据本身具有权限与安全等级,下游数据的安全等级不应该低于上游的安全等级,否则会有权限泄露风险。
可以基于血缘,通过扫描高安全等级节点的下游,查看下游节点是否与上游节点权限保持一致,来排除权限泄露、数据泄露等安全合规风险。
五、数据血缘落地方案
目前业内常见的落地数据血缘系统以及应用,主要有以下三种方式:
1、采用开源系统:
Atlas、Metacat、Datahub等
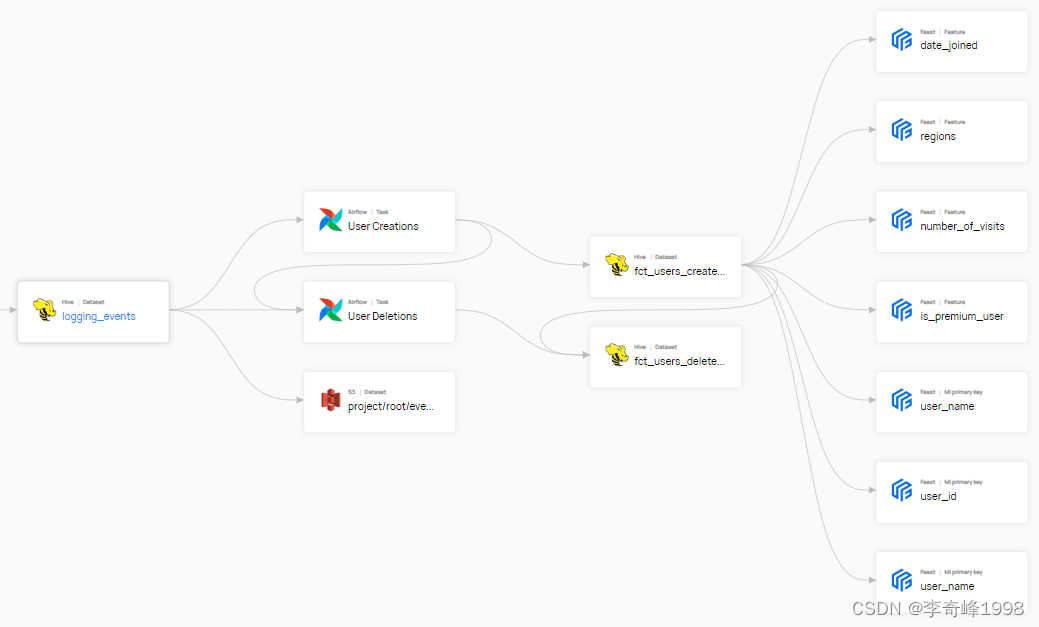
采用开源系统最大的优点是投入成本较低,但是缺点主要包括
1、适配性较差,开源方案无法完全匹配公司现有痛点。
2、二开成本高,需要根据开源版本进行定制化开发。
2、厂商收费平台:
亿信华辰,网易数帆等
此类数据平台中会内置数据血缘管理系统,功能较为全面,使用方便。但是同样也有以下缺点:
1、贵
2、需要ALL IN厂商平台,为保障数据血缘的使用,数据业务需要全部迁移到厂商平台中。
3、自建
通过图数据库、后端、前端自建数据血缘管理系统,此方案开发投入较大,但是有以下优点
1、因地制宜,可根据核心痛点定制化开发元数据及数据血缘系统。
2、技术积累,对于开发人员来说,从0-1开发数据血缘系统,可以更深刻的理解数据业务。
3、平台解耦,独立于数据平台之外,数据血缘的开发不会对正常业务造成影响。
六、如何自建数据血缘系统
1、明确需求,确定边界
在进行血缘系统构建之前,需要进行需求调研,明确血缘系统的主要功能,从而确定血缘系统的最细节点粒度,实体边界范围。
例如节点粒度是否需要精确到字段级,或是表级。一般来说,表级粒度血缘可以解决75%左右的痛点需求, 字段级血缘复杂度较表级血缘高出许多,如果部门人数较少,可以考虑只精确到表级粒度血缘。
常见的实体节点包括:任务节点、库节点、表节点、字段节点、指标节点、报表节点、部门节点等。血缘系统可以扩展数据相关的实体节点,可以从不同的场景查看数据走向,例如表与指标,指标与报表的血缘关系。但是实体节点的范围需要明确,不可无限制的扩展下去。
明确需求,确定节点粒度与范围之后,才可根据痛点问题给出准确的解决方案,不至于血缘系统越建越臃肿,提高ROI(投入产出比)。
2、构建元数据管理系统
目前市面上所有的血缘系统都需要依赖于元数据管理系统而存在。
元数据作为血缘的基础,一是用于构建节点间的关联关系,二是用于填充节点的属性,三是血缘系统的应用需要基于元数据才能发挥出最大的价值。所以构建血缘系统的前提一定是有一个较全面的元数据。
元数据管理系统将会在下周发布的《元数据管理系统落地实施》文章中进行详细讲解
3、技术选型:图数据库
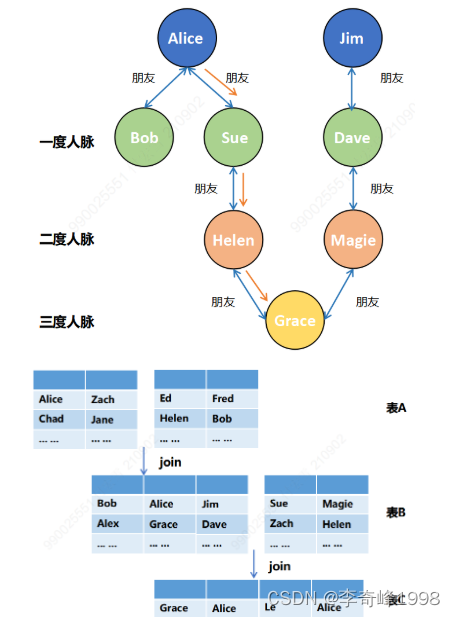
目前业内通常采用图数据库进行血缘关系的存储。
对于血缘关系这种层级较深,嵌套次数较多的应用场景,关系型数据库必须进行表连接的操作,表连接次数随着查询的深度增大而增多,会极大影响查询的响应速度。
而在图数据库中,应用程序不必使用外键约束实现表间的相互引用,而是利用关系作为连接跳板进行查询,在查询关系时性能极佳,而且利用图的方式来表达血缘关系更为直接。
下图为图数据库与关系型数据库在查询人脉时的逻辑对比:
4、血缘关系录入:自动解析and手动登记
自动解析:
获取到元数据之后,首先可以根据元数据表中的SQL抽取语句,通过SQL解析器可自动化获取到当前表的来源表【SQL解析器推荐jsqlparse】,并进行血缘关系录入。
手动登记:
如果当前表无SQL抽取语句,数据来源为手动导入、代码写入、SparkRDD方式等无法通过自动化方式确定来源表的时候,我们需要对来源表进行手动登记,然后进行血缘关系的录入。
血缘关系录入需要基于图数据库进行,图数据库的建模、语句与关系型数据库截然不同,如有疑问可以加入社区交流群进行解答。
5、血缘可视化
血缘系统构建完成后,为了能够更好的体现血缘价值,量化产出,需要进行血缘可视化的开发,分为两步:
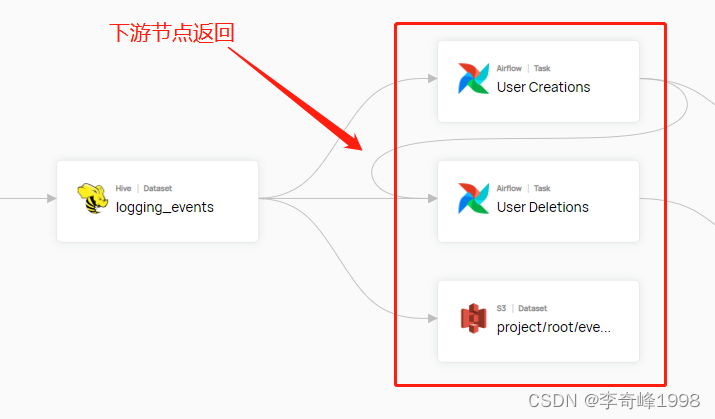
(1)链路-属性展示:
根据具体节点,通过点击操作,逐级展示血缘节点间的链路走向与涉及到的节点属性信息。

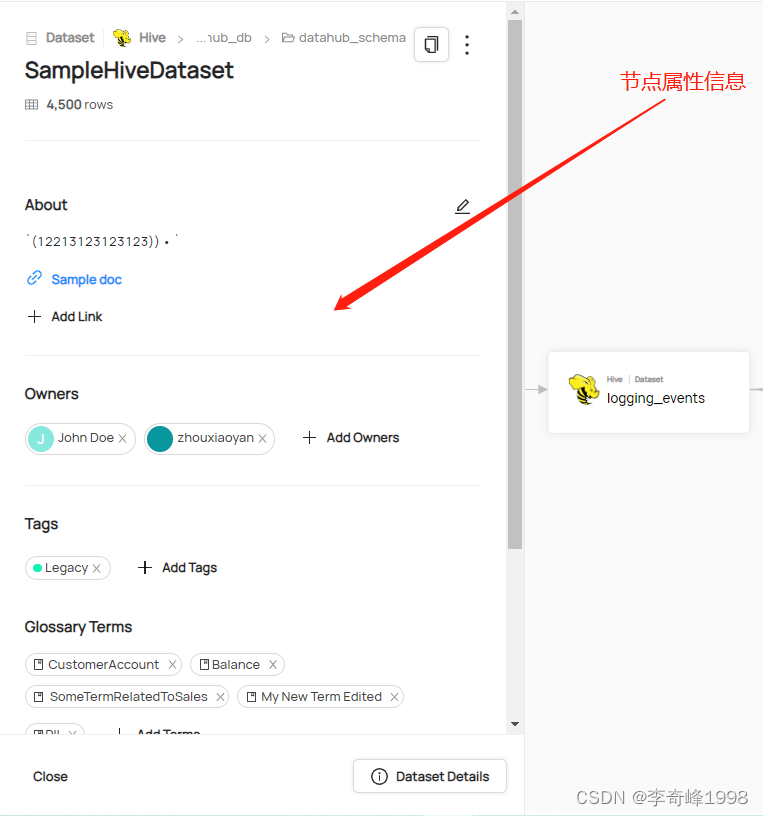
(2)节点操作:
基于可视化的血缘节点与当前节点附带的元数据属性,我们可以设想一些自动化操作例如:
节点调度:直接基于血缘开启当前表节点的调度任务
属性修改:通过前端修改当前节点的元数据属性并保存
还有更多可视化操作可以加入社区交流群进行讨论
6、血缘统计分析
数据血缘构建完成后,我们可以做一些统计分析的操作,从不同层面查看数据的分布与使用情况,从而支撑业务更好更快更清晰。
以我们团队举例,在工作过程中,我们需要以下血缘统计用于支撑数据业务,例如:
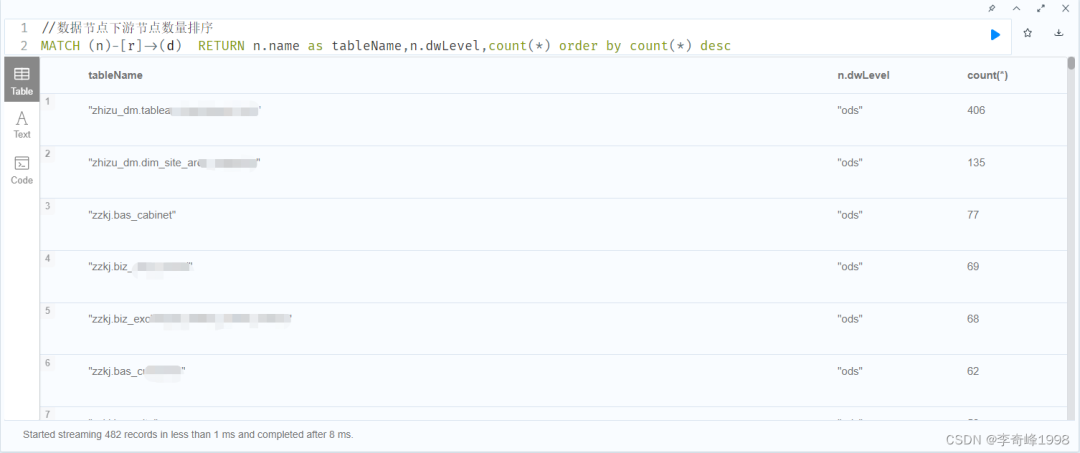
数据节点下游节点数量排序,用于评估数据价值及其影响范围
查询当前节点的所有上游节点,用于业务追踪溯源

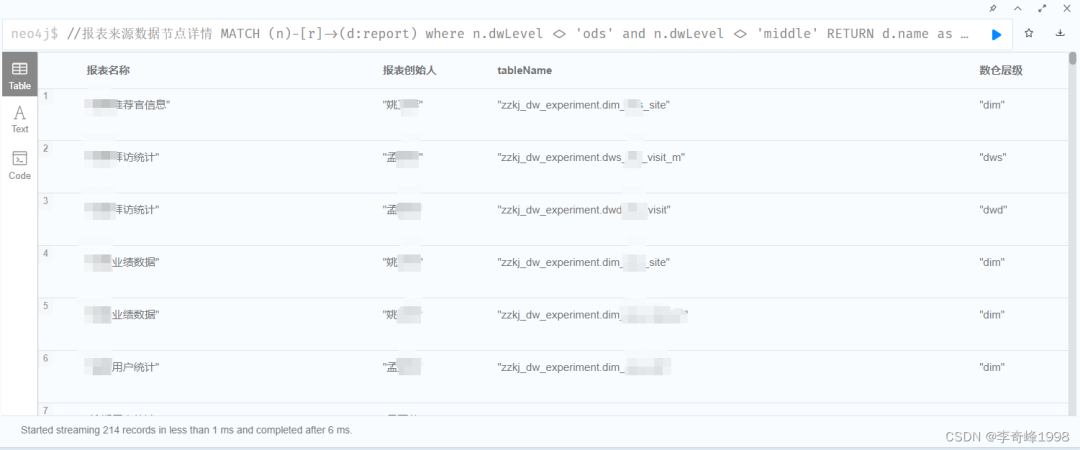
数据节点输出报表信息详情统计,用于报表的上架与更新
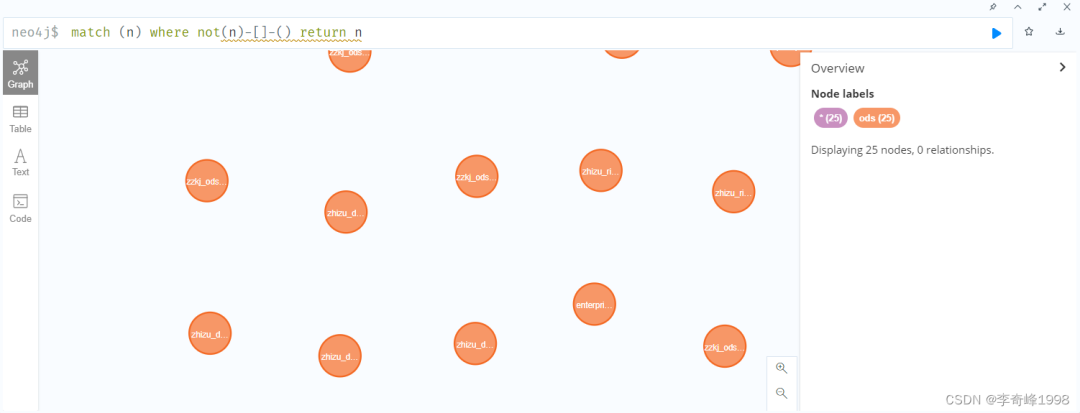
查询孤岛节点,即无上下游节点的节点,用于数据删除的依据
7、血缘驱动业务开展
数据血缘构建完成,统计分析结果也有了,业务痛点也明确了,接下来我们即可利用数据血缘驱动业务更好更快开展。
我们团队目前落地的血缘相关业务有以下几点:
(1)影响范围告警:
将血缘关系与调度任务打通,监测当前血缘节点的调度任务,如果当前节点调度出现异常,则对当前节点的所有下游节点进行告警。
(2)异常原因探查:
还是将血缘关系与调度任务打通,监测当前血缘节点的调度任务,如果当前节点调度出现异常,则会给出当前节点的直接上游节点,用于探查异常原因。
(3)异常链路一键恢复:
基于上一应用,异常原因定位并且修复完成之后,可以通过血缘系统,一键恢复当前数据节点的所有下游节点调度任务,真正实现一键操作。
团队目前已经基于血缘系统构建出一整套的异常调度影响范围告警->异常原因探查->异常链路一键恢复的故障响应修复机制。
(4)支撑数据下架:
目前团队已经根据探查孤岛节点即无上下游节点的节点,累计归档数据表628张,节省了13%的存储空间。
(5)数据质量监控:
对当前血缘中所有节点输出的下有节点数量进行排序,可以精确的判断某张表的影响范围大小,从而可以根据此对高排序表进行数据质量的监控。
(6)数据标准化监控:
如果当前公司制定了基于库、表、字段的命名规范,我们可以通过探查血缘中的所有数据节点,并命名规范进行匹配,得到不符合规范的库、表、字段进行整改。
当然了,此业务仅基于元数据也可实现,放在此处属于博主强行升华了。
(7)数据安全审计:
团队基于用户职级、部门、操作行为等权重对目前的库表进行了数据权限等级划分,权限等级越高,当前表的安全级别越高。
团队基于血缘进行数据全链路的安全等级监测,如果发现下游节点安全等级低于上游节点,则会进行告警并提示整改。确保因为安全等级混乱导致数据泄露。
八、血缘系统评价标准
在推动数据血缘落地过程中,经常会有用户询问:血缘质量如何?覆盖场景是否全面?能否解决他们的痛点?做出来好用吗?
于是我也在思考,市面上血缘系统方案那么多,我们自建系统的核心优势在哪里,血缘系统的优劣从哪些层次进行评价,于是我们团队量化出了以下三个技术指标:
1、准确率
定义: 假设一个任务实际的输入和产出与血缘中该任务的上游和下游相符,既不缺失也不多余,则认为这个任务的血缘是准确的,血缘准确的任务占全量任务的比例即为血缘准确率。
准确率是数据血缘中最核心的指标,例如影响范围告警,血缘的缺失有可能会造成重要任务没有被通知,造成线上事故。
我们在实践中通过两种途径,尽早发现有问题的血缘节点:
人工校验: 通过构造测试用例来验证其他系统一样,血缘的准确性问题也可以通过构造用例来验证。实际操作时,我们会从线上运行的任务中采样出一部分,人工校验解析结果是否正确。
用户反馈: 全量血缘集合的准确性验证是个漫长的过程,但是具体到某个用户的某个业务场景,问题就简化多了。实际操作中,我们会与一些业务方深入的合作,一起校验血缘准确性,并修复问题。
2、覆盖率
定义: 当有数据资产录入血缘系统时,则代表数据血缘覆盖了当前数据资产。被血缘覆盖到的数据资产占所有数据资产的比例即为血缘覆盖率。
血缘覆盖率是比较粗粒度的指标。作为准确率的补充,用户通过覆盖率可以知道当前已经支持的数据资产类型和任务类型,以及每种覆盖的范围。
在内部,我们定义覆盖率指标的目的有两个,一是我方比较关注的数据资产集合,二是寻找当前业务流程中尚未覆盖的数据资产集合,以便于后续血缘优化。
当血缘覆盖率低时,血缘系统的应用范围一定是不全面的,通过关注血缘覆盖率,我们可以知晓血缘的落地进度,推进数据血缘的有序落地。
3、时效性
定义: 从数据资产新增和任务发生修改的时间节点,到最终新增或变更的血缘关系录入到血缘系统的端到端延时。
对于一些用户场景来说,血缘的时效性并没有特别重要,属于加分项,但是有一些场景是强依赖。不同任务类型的时效性会有差异。
例如:故障影响范围告警以及恢复,是对血缘实时性要求很高的场景之一。如果血缘系统只能定时更新T-1的状态,可能会导致严重业务事故。
提升时效性的瓶颈,需要业务系统可以近实时的将任务相关的修改,以通知形式发送出来,并由血缘系统进行更新。
参考文献:
[1] 杨明皓:数据血缘的管控方法及应用场景
[2] Michael Adjei:什么是数据血缘?数据血缘的五大好处
[3] 李俊杰:2022 数据血缘基本指南
[4] 字节跳动:详解数据血缘的「整体设计」与「评价方案」
[5] twt社区:基于图数据库的元数据血缘关系分析技术研究与实践