

一、前言
Data lineage includes the data origin, what happens to it and where it moves over time. Data lineage gives visibility while greatly simplifying the ability to trace errors back to the root cause in a data analytics process.
──百科Data lineage.
大数据时代,数据的来源极其广泛,各种类型的数据在快速产生,数据也是爆发性增长。从数据的产生,通过加工融合流转产生新的数据,到最终消亡,数据之间的关联关系可以称之为数据血缘关系。
数据血缘是元数据管理、数据治理、数据质量的重要一环,追踪数据的来源、处理、出处,对数据价值评估提供依据,描述源数据流程、表、报表、即席查询之间的流向关系,表与表的依赖关系、表与离线ETL任务,调度平台,计算引擎之间的依赖关系。数据仓库是构建在Hive之上,而Hive的原始数据往往来自于生产DB,也会把计算结果导出到外部存储,异构数据源的表之间是有血缘关系的。
数据血缘用途:
- 追踪数据溯源:当数据发生异常,帮助追踪到异常发生的原因;影响面分析,追踪数据的来源,追踪数据处理过程。
- 评估数据价值:从数据受众、更新量级、更新频次等几个方面给数据价值的评估提供依据。
- 生命周期:直观地得到数据整个生命周期,为数据治理提供依据。
- 安全管控:对源头打上敏感等级标签后,传递敏感等级标签到下游。
本文介绍携程数据血缘如何构建及应用场景。第一版T+1构建Hive引擎的表级别的血缘关系,第二版近实时构建Hive,Spark,Presto多个查询引擎和DataX传输工具的字段级别血缘关系。
二、构建血缘的方案
2.1 收集方式
方案一:只收集SQL,事后分析。
当SQL执行结束,收集SQL到DB或者Kafka。
优点:当计算引擎和工具不多的时候,语法相对兼容的时候,用Hive自带的LineageLogger重新解析SQL可以获得表和字段级别的关系。
缺点:重放SQL的时候可能元数据发生改变,比如临时表可能被Drop,没有临时自定义函数UDF,或者SQL解析失败。
方案二:运行时分析SQL并收集。
当SQL执行结束后立即分析Lineage,异步发送到Kafka。
优点:运行时的状态和信息是最准确的,不会有SQL解析语法错误。
缺点:需要针对各个引擎和工具开发解析模块,解析速度需要足够快。
2.2 开源方案
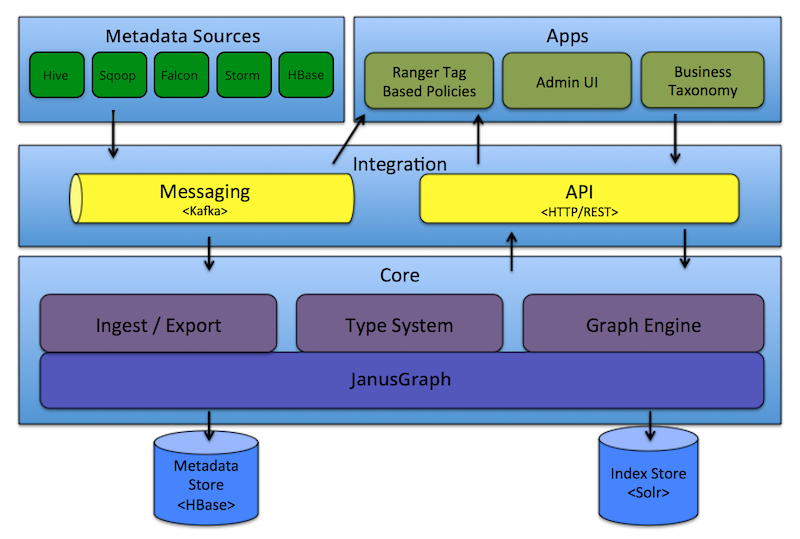
Apache Atlas
Apache Atlas是Hadoop社区为解决Hadoop生态系统的元数据治理问题而产生的开源项目,它为Hadoop集群提供了包括数据分类、集中策略引擎、数据血缘、安全和生命周期管理在内的元数据治理核心能力。官方插件支持HBase、Hive、Sqoop、Storm、Storm、Kafka、Falcon组件。
Hook在运行时采集血缘数据,发送到Kafka。Atlas消费Kafka数据,将关系写到图数据库JanusGraph,并提供REST API。
其中Hive Hook支持表和列级别血缘,Spark需要使用GitHub的hortonworks-spark/spark-atlas-connector,不支持列级别,Presto则不支持。
Linkedin DataHub
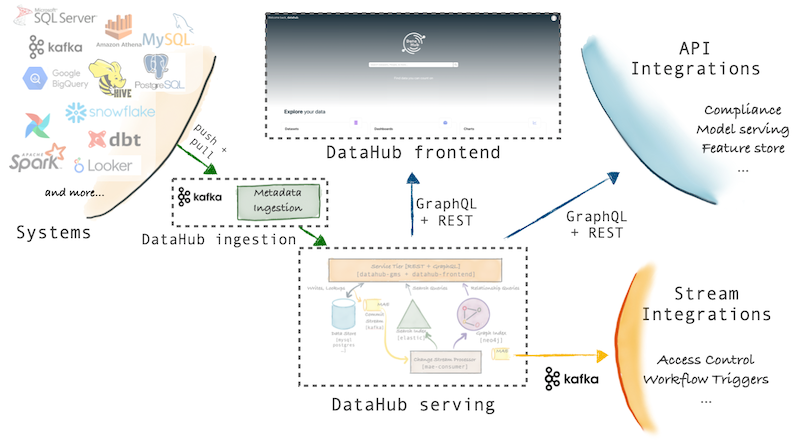
WhereHows项目已于2018年重新被LinkedIn公司设计为DataHub项目。它从不同的源系统中采集元数据,并进行标准化和建模,从而作为元数据仓库完成血缘分析。
社区提供了一个Demo,演示地址:https://demo.datahubproject.io/
与Airflow集成较好,支持数据集级别血缘,字段级别在2021Q3的Roadmap。
三、携程方案
携程采用了方案二,运行时分析SQL并收集分析结果到Kafka。由于开源方案在现阶段不满足需求,则自行开发。
由于当时缺少血缘关系,对数据治理难度较大,表级别的血缘解析难度较低,表的数量远小于字段的数量,早期先快速实现了表级别版本。
在16-17年实现和上线了第一个版本,收集常用的工具和引擎的表级别的血缘关系,T+1构建关系。
在19年迭代了第二个版本,支持解析Hive,Spark,Presto多个查询引擎和DataX传输工具的字段级别血缘关系,近实时构建关系。
四、第一个版本-表级别血缘关系
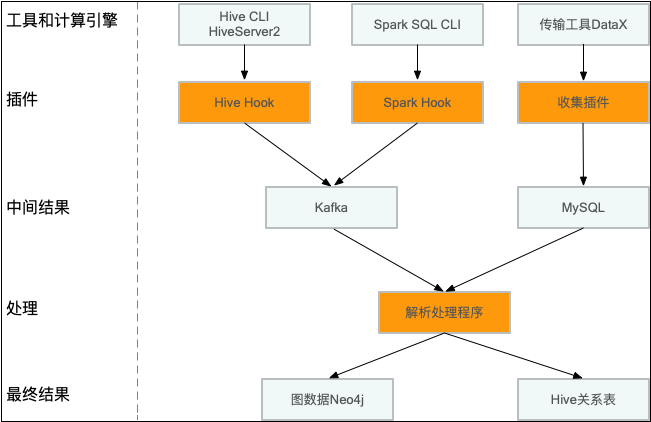
4.1 处理流程
针对Hive引擎开发了一个Hook,实现ExecuteWithHookContext接口,从HookContext可以获得执行计划,输入表,输出表等丰富信息,异步发送到Kafka,部署的时候在hive.exec.post.hooks添加插件即可。
在17年引入Spark2后,大部分Hive作业迁移到Spark引擎上,这时候针对Spark SQL CLI快速开发一个类似Hive Hook机制,收集表级别的血缘关系。
传输工具DataX作为一个异构数据源同步的工具,单独对其开发了收集插件。
在经过解析处理后,将数据写到图数据库Neo4j,提供元数据系统展示和REST API服务,落地成Hive关系表,供用户查询和治理使用。
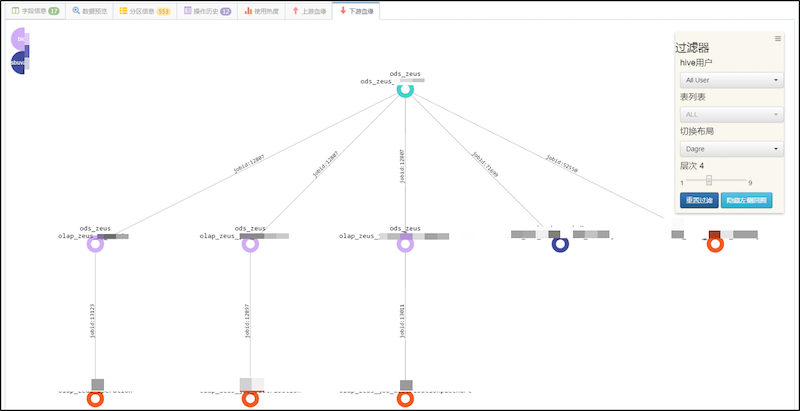
4.2 效果
在元数据系统上,可以查看一张表多层级的上下游血缘关系,在关系边上会有任务ID等一些属性。
4.3 痛点
- 随着计算引擎的增加,业务的增长,表级别的血缘关系已经不满足需求。
- 覆盖面不足,缺少Spark ThriftServer , Presto引擎,缺少即席查询平台,报表平台等。
- 关系不够实时,期望写入表后可以快速查询到关系,用户可以直观查看输入和输出,数据质量系统,调度系统可以根据任务ID查询到输出表,对表执行质量校验任务。
- 图数据库Neo4j社区版为单机版本,存储数量有限,稳定性欠佳,当时使用的版本较低,对边不能使用索引(3.5支持),这使得想从关系搜索到关联的上下游较为麻烦。
五、第二版本-字段级别血缘关系
之前实现的第一个版本,对于细粒度的治理和追踪还不够,不仅缺少对字段级别的血缘关系,也不支持采集各个系统的埋点信息和自定义扩展属性,难以追踪完整链路来源,并且关系是T+1,不够实时。
针对各个计算引擎和传输工具DataX开发不同的解析插件,将解析好的血缘数据发送到Kafka,实时消费Kafka,把关系数据写到分布式图数据JanusGraph。
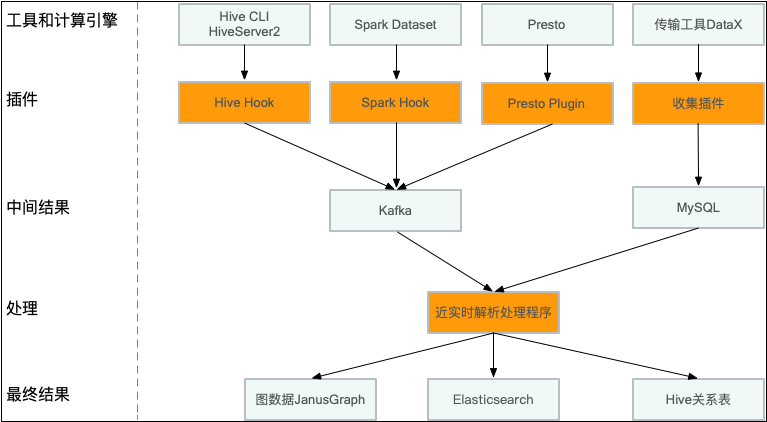
5.1 传输工具DataX
阿里开源的Druid是一个 JDBC 组件库,包含数据库连接池、SQL Parser 等组件。通过重写MySqlASTVisitor、SQLServerASTVisitor来解析MySQL / SQLServer的查询SQL,获得列级别的关系。
.2 计算引擎
计算引擎统一格式,收集输入表、输出表,输入字段、输出字段,流转的表达式等一些信息。
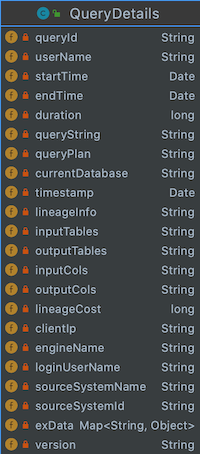
Hive
参考 org.apache.hadoop.hive.ql.hooks.LineageLogger 实现,异步发送血缘数据到 Kafka。
Atlas的HiveHook也是实现ExecuteWithHookContext接口,从HookContext获得LineageInfo,也可以参考HIVE-19288 引入的org.apache.hadoop.hive.ql.hooks.HiveProtoLoggingHook,采集更多引擎相关的信息。
其中遇到几个问题:
- 通过HiveServer2执行获取的start time不正确
HIVE-10957 QueryPlan’s start time is incorrect in certain cases
- 获取执行计划空指针,导致收集失败
HIVE-12709 further improve user level explain
获取执行计划有可能出现卡住,可以加个调用超时。
Spark
前置条件:引入 SPARK-19558 Add config key to register QueryExecutionListeners automatically,实现自动注册QueryExecutionListener。
实现方式:通过实现QueryExecutionListener接口,在onSuccess回调函数拿到当前执行的QueryExecution,通过LogicalPlan的output方法,获得所有Attribute,利用NamedExpression的exprId映射关系,对其进行遍历和解析,构建列级别关系。
覆盖范围:Spark SQL CLI、Thrift Server、使用Dataset/DataFrame API(如spark-submit、spark-shell、pyspark)
遇到问题:
- 使用analyzedPlan而不是optimizedPlan,optimizer的执行计划可能会丢失一些信息,可以在analyzedPlan的基础上apply一些有助于分析的Rule,如CombineUnions。
- 传递的初始化用的hiveconf/hivevar变量被Thrift Server忽略,导致初始化Connection没有办法埋点。
打上Patch SPARK-13983 ,可以实现第一步,传递变量,但是这个变量在每次执行新的statement都重新初始化,导致用户set的变量不可更新。后续给社区提交PR SPARK-26598,修复变量不可更新的问题。
SPARK-13983 Fix HiveThriftServer2 can not get “–hiveconf” and “–hivevar” variables since 2.0
SPARK-26598 Fix HiveThriftServer2 cannot be modified hiveconf/hivevar variables
- Drop Table 的限制,DropTableCommand执行成功的时候,该表不一定在之前存在过,如果在Drop之前存在过,元数据也已经被删除了,无从考证。
在DropTableCommand增加了一个标志位,真正在有执行Drop操作的话再置为True,保证收集的血缘数据是对的。
- 使用Transform用户自定义脚本的限制
Transform不像java UDF,只输入需要用到的字段即可,而是需要将所有后续用到的字段都输入到自定义脚本,脚本再决定输出哪些字段,这其中列与列之间的映射关系无法通过执行计划获得,只能简单的记录输出列的表达式,如transform(c1,c2,c3) script xxx.py to c4。
Presto
开发Presto EventListener Plugin,实现EventListener接口,从queryCompleted回调函数的QueryCompletedEvent解析得到相应的信息。
上线的时候遇到一个无法加载Kafka加载StringSerializer的问题(StringSerializer could not be found)。
Kafka客户端使用 Class.forName(trimmed, true, Utils.getContextOrKafkaClassLoader()) 来加载Class,优先从当前线程的ContextClassLoader加载,与Presto的ThreadContextClassLoader有冲突,需要初化始KafkaProducer的时候,将ContextClassLoader暂时置为NULL。https://stackoverflow.com/a/50981469/1673775
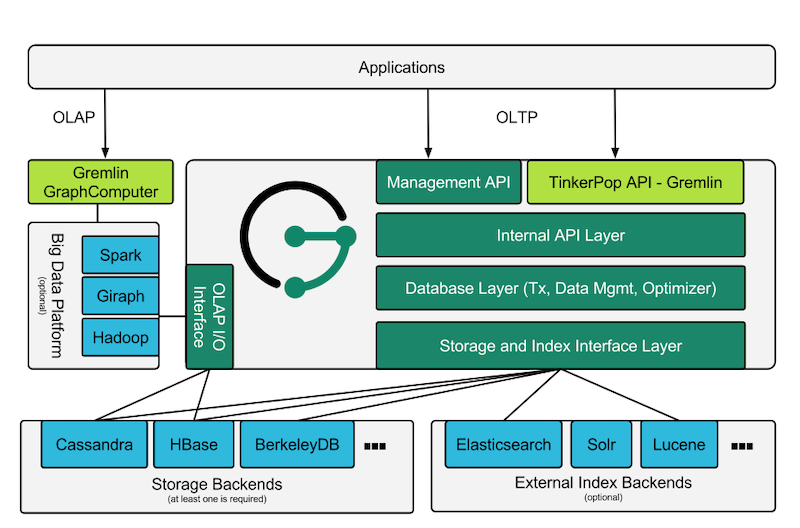
5.3 图数据库JanusGraph
JanusGraph是一个开源的分布式图数据库。具有很好的扩展性,通过多机集群可支持存储和查询数百亿的顶点和边的图数据。JanusGraph是一个事务数据库,支持大量用户高并发地执行复杂的实时图遍历。
生产上,存储我们使用Cassandra,索引使用Elasticsearch,使用Gremlin查询/遍历语言来读写JanusGraph,有上手难度,熟悉Neo4j的Cypher语法可以使用cypher-for-gremlin plugin。
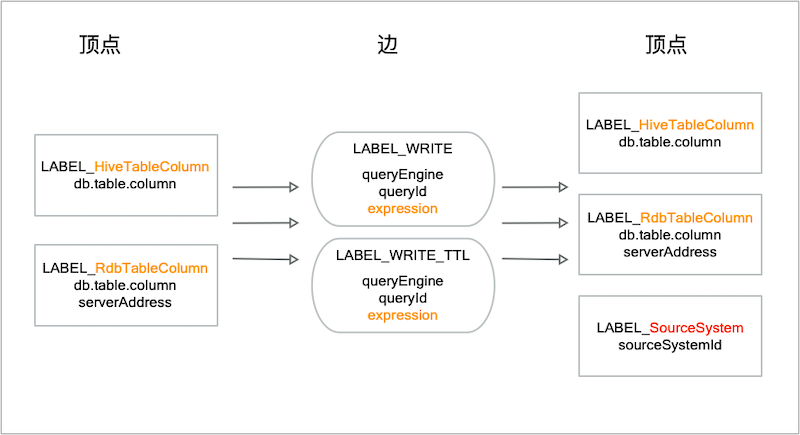
以下是数据血缘写入图数据库的模型,Hive字段单独为一个Lable,关系型DB字段为一个Label,关系分两种,LABELWRITE,LABELWRITE_TTL。
只有输入没有输出(Query查询操作),只有输出没有输入(建表等DDL操作)也会强制绑定一个来源系统的ID及扩展属性。
在生产上使用JanusGraph,存储亿级的血缘关系,但是在开发过程中也遇到了一些性能问题。
- 写入速度优化
以DB名+表名+字段名作为唯一key,实现getOrCreateVertex,并对vertex id缓存,加速顶点的加载速度。
- 关系批量删除
关系LABELWRITETTL表示写入的关系有存活时间(TTL-Time to live),这是因为在批量删除关系的时候,JanusGraph速度相当慢,而且很容易OOM。比如要一次性删除,Label为WRITE,x=y,写入时间小于等于某个时间的边,这时候Vertex和Edge load到内存中,容易OOM。
g.E().hasLabel(“WRITE”).has(“x”,eq(“y”)).has(“publishedDate”,P.lte(new Date(1610640000))).drop().iterate()
尝试使用多线程+分批次的方式,即N个线程,每个线程删除1000条,速度也不太可接受。
这时候采用了折中的方案,需要删除关系用另外一种Label来表示,并在创建Label指定了TTL,由于Cassandra支持cell level TTL,所以边的数据会自动被删除。但是ES不支持TTL,实现一个定时删除ES过期数据即可。
5.4 覆盖范围
Zeus调度平台 (ETL操作INSERT、CTAS,QUERY)
Ad-Hoc即席查询平台 (CTAS,QUERY)
报表平台 (QUERY)
元数据平台 (DDL操作)
GPU平台 (PySpark)
通过ETL任务ID,查询任务ID,报表ID,都可以获取到输入,输出的表和字段的关系。
5.5 局限
使用MapReduce、Spark RDD读写HDFS的血缘暂时没有实现。
思路可以在JobClient.submitJob的时候采集输入和输出路径,又或者通过HDFS的AuditLog、CallerContext来关联。
5.6 效果
在第一版使用图的方式展示血缘关系,在上下游关系较多的时候,显示较为混乱,第二版改成树状表格的方式展示。
字段operator在调度系统Zeus被转换成hive_account,最后输出是ArtNova报表系统的一张报表。
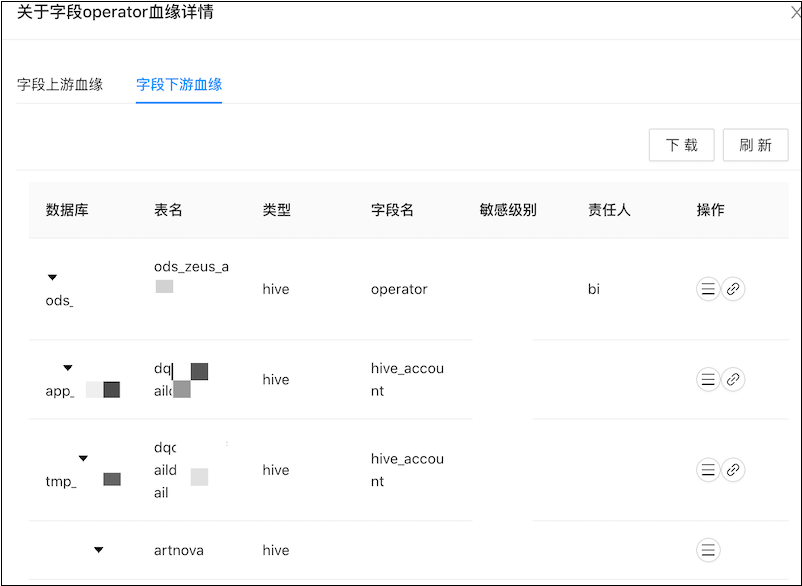
六、实际应用场景
6.1 数据治理
- 通过血缘关系筛选,每天清理数千张未使用的临时表,节约空间。
- 作为数据资产评估的依据,统计表、字段读写次数,生成的表无下游访问,包括有没有调度任务,报表任务,即席查询。
6.2 元数据管理
- 统计一张表的生成时间,而不是统计整个任务的完成时间。
- 数据异常,或者下线一张表、一个字段的时候,可以找到相关的ETL任务或者报表任务,及时通知下游。
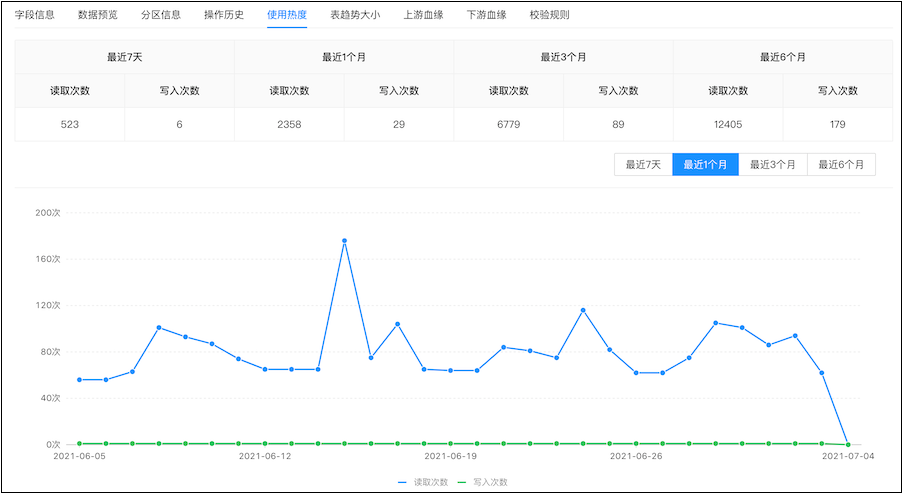
- 统计表的使用热度,显示趋势。
6.3 调度系统
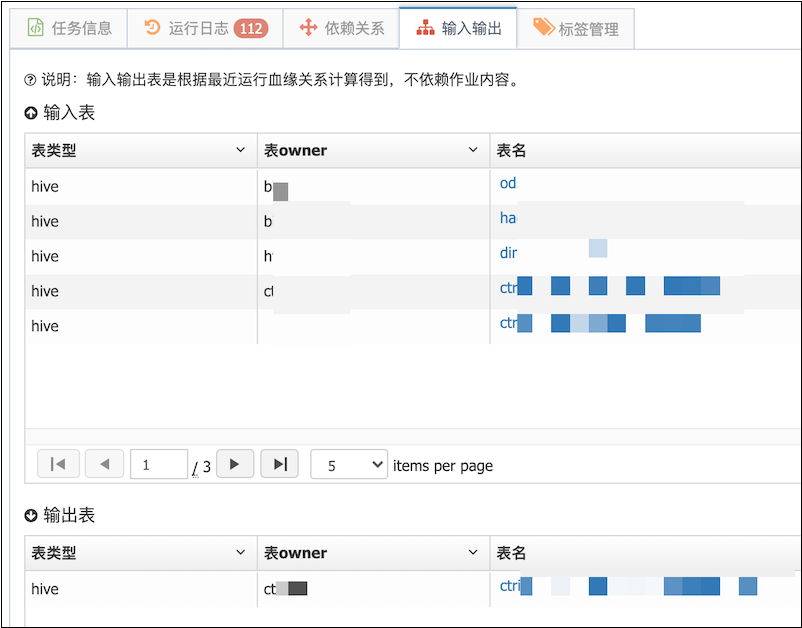
得益于在图数据库JanusGraph可以使用关系边的key作为索引,可以根据任务ID可以轻松获得该任务输入和输出表。
- 当配置一个任务A的依赖任务列表的时候,可以使用推荐依赖,检查依赖功能,获得任务A的所有输入表,再通过输入的表获得写入任务ID列表,即为任务A所需依赖的任务列表。
- 在任务结束后,获取该任务所有输出的表,进行预配的规则进行数据质量校验。
6.4 敏感等级标签
当源头的数据来自生产DB时,生产DB有些列的标签已打上了敏感等级,通过血缘关系,下游的表可以继承敏感等级,自动打上敏感标签。
七、总结
以上描述了携程如何构建表和字段级别的血缘关系,及在实际应用的场景。
随着业务需求和数据的增长,数据的加工流程越来越复杂,构建一套数据血缘,可以轻松查询到数据之间的关系,进行表和字段级的血缘追溯,在元数据管理,数据治理,数据质量上承担重要一环。
作者简介:cxzl25,携程软件技术专家,关注大数据领域生态建设,对分布式计算和存储、调度等方面有浓厚兴趣。
本文来源:微信公众号携程技术。