

导读 天下数仓工程师苦值班久矣,面对大规模的数据处理任务,复杂的处理链路与层次结构,数据团队在数据稳定性保障方面通常面临较大的压力。今天主要以平台建设方的视角,结合稳定性治理的实际场景,将阿里多年来基于自身特点总结出的数据稳定性治理的实践经验与探索,与大家进行分享。
全文目录:
- 阿里在数据稳定性保障中遇到的问题
- 阿里数据稳定性治理方案
- Dataworks基线运维实践
- 事前稳定性治理探索
分享嘉宾|冉秋萍,阿里云 DataWorks 产品专家
编辑整理|曹洪霞 厦门象屿
内容校对|李瑶
出品社区|DataFun
01 阿里在数据稳定性保障中遇到的问题
1. 阿里大数据工作开展架构
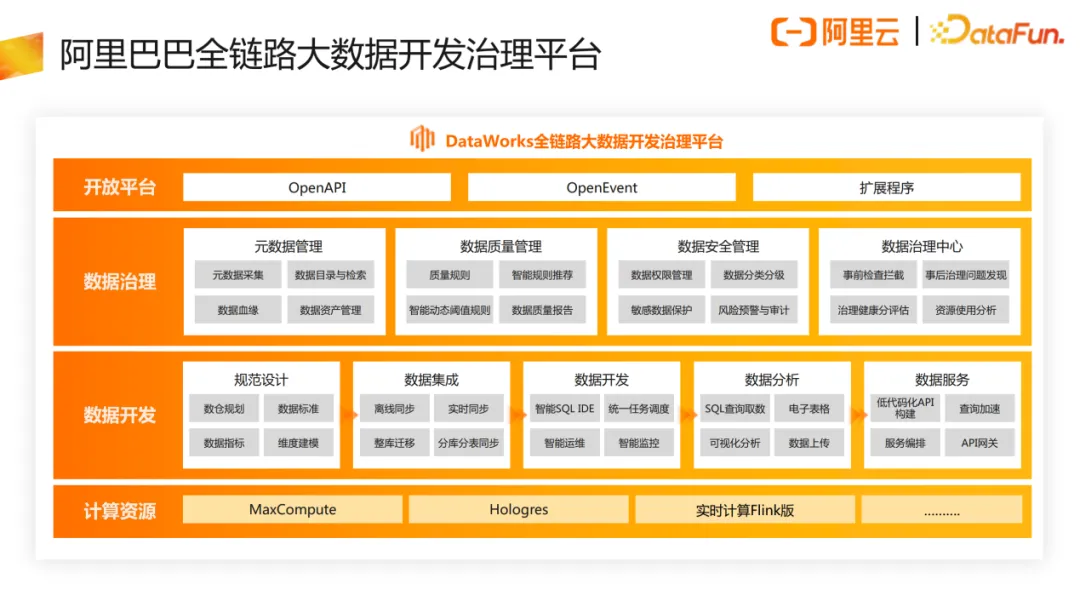
阿里大数据计算的离线数据处理部分,主要是基于MaxCompute引擎+DataWorks大数据开发治理平台来完成日常的数据开发管理工作。平台产品方在响应数据研发、数据管理等团队的数据治理需求过程中,通过沉淀的相关规范和方法论,逐步积累落地到平台产品模块中,形成了完整的大数据开发治理链路。
阿里内部通过这样一套统一的大数据计算技术体系,来支撑不同的业务的发展和创新。从最早的淘宝、天猫电商业务,到后续的优酷、高德、菜鸟等板块,业务的蓬勃发展,带来了单日EB级的数据处理量,DataWorks上单日千万级别的数据处理调度实例数,以及高达50多种的复杂业务依赖关系。
高并发的数据任务背后,是上万名平台数据工作者,进行日常的数据加工与运维管理分析,以满足业务对于各种场景下的数据要求以及各类数据治理需求。

2. 数据稳定性问题的常见表现
通常业务方对于数据的基本要求为每天能够准时看到正确的数据,越重视数据即时交互与用户体验的应用场景,对于数据稳定性的要求也越高。因此数据团队除了进行本身的数据研发以外,最关键的问题是保障数据的稳定产出。
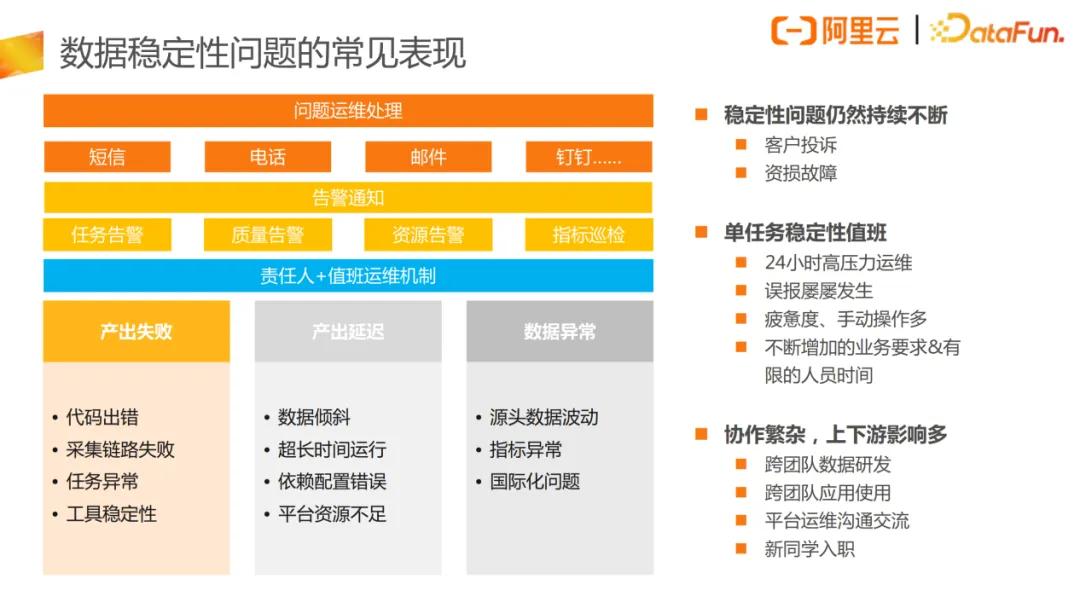
面对如此大规模的数据处理任务、如此复杂的处理链路与层次结构,数据团队在稳定性保障方面也面临不小的压力,数据运维机制应运而生。最直接的方式是用人力来保障数据产出。针对数据问题,平台提供了各类告警方式,比如通过短信、电话、邮件、钉钉等快速地发送告警信息。
但在人力保障过程中,一方面,大量的离线处理在夜间执行,出现问题后值班人员需要整夜盯盘和响应异常;另一方面,问题处理可能需依赖上下游协调,跨团队、跨业务的协作排查效率较低;有的还需等待集群计算资源,这导致值班工作变成辛苦、低效且耗时很长的过程。
同时,这种运维值班加单任务负责人问题响应机制并没有在本质上解决数据稳定性问题,数据产出失败、产出延迟、数据异常等问题依然屡屡发生。这些问题通常由多种因素引起,有可能是代码本身或配置错误,有可能是平台资源的问题,也有可能是上游源头侧的级联问题,甚至是人员误操作、系统误识别及误报等问题。

以上图中的真实案例为例,问题的解决也常常面临着责任机制、优先级分配、上下游协作机制等现实资源瓶颈问题,导致处理效果不佳。所引起的客户投诉和资损故障,在不断地提醒数仓团队重视数据稳定性问题。
02 阿里数据稳定性治理方案
1. 数据稳定性治理原则

实际上,数据稳定性保障的问题根源在于人力资源及计算资源是有限的,大量的数据交互与人员交互又是不可避免的。为了解决复杂数据链路系统里的这些问题,数据团队在不断地升级优化数据稳定性治理方案。基于数据是服务于业务的前提,结合业务方对于客户的承诺,以及业务的优先级来评估需要投入的运维力量,设置对应的数据产出约定。
数据稳定性治理的原则,即为,通过合理的人力协作及治理工作,高效保障业务所需的重点数据,能及时、准确产出,满足数据对业务的约定。实现重要数据重点保障,严重问题优先处理,故障机制挂钩责任机制。
2. 如何定义重点数据
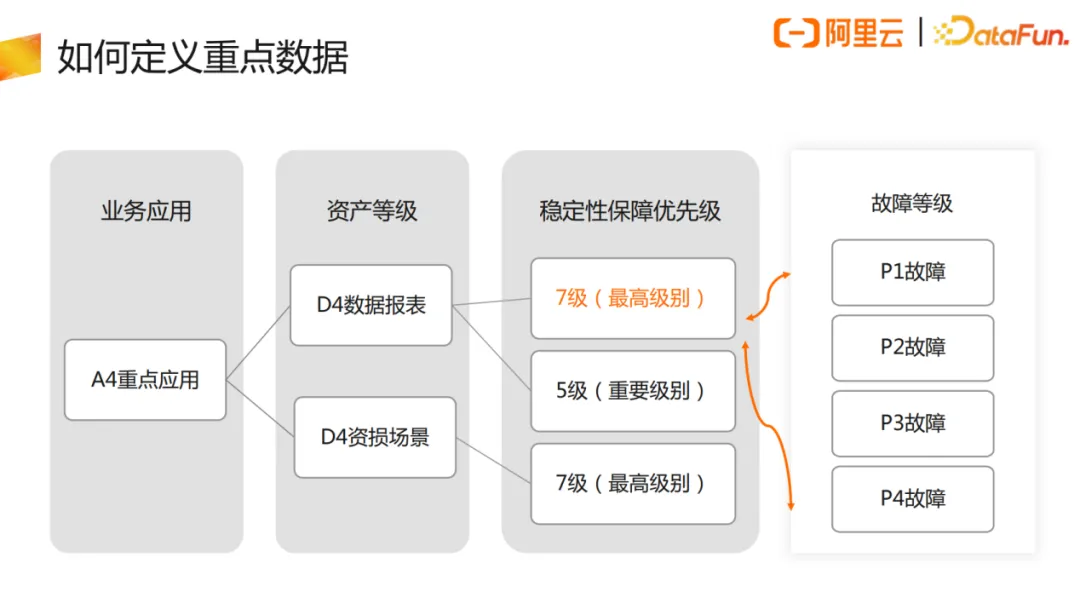
首先要定义出重点数据。通过对业务部门的应用进行盘点,划分应用等级,数据资产的话也会根据其支撑的业务应用去评定资产等级,高等级资产一般会配备高等级的稳定性保障。有了这样的级别标签之后,则可以建立配套的故障等级机制。一般来说,数据异常时长越久、资产等级越高,对应的故障级别越高。故障会有对应的责任团队去认领、复盘,以及保障运维资源。
3. 如何保障重点数据的及时性与准确性
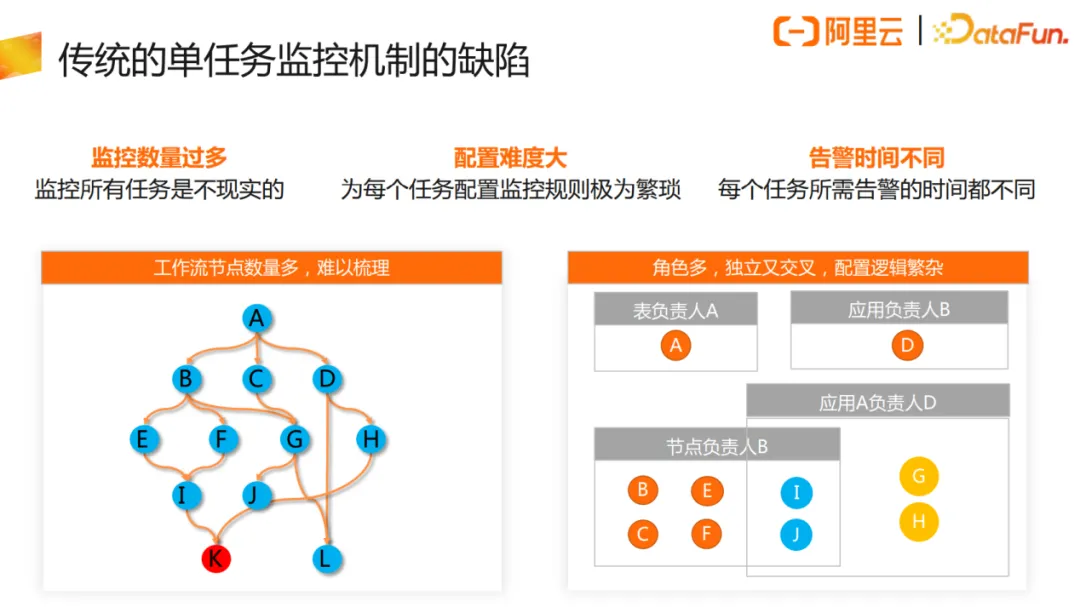
那么如何去保障数据重点数据的及时性和准确性呢?以单点运维保障机制来讲,建设初期的时候,数据节点少,数据链路少,可以通过责任人做监控运维的方式,对每个节点进行监控。但是在数据链路复杂了之后,不同的角色都要对自己负责的单点任务或者单点表去进行梳理和运维,导致在配置单点监控告警时,配置逻辑繁杂,且基于人肉识别的方式难以准确地完成监控运维保障。传统的单任务监控机制只适用于小规模团队的监控配置。
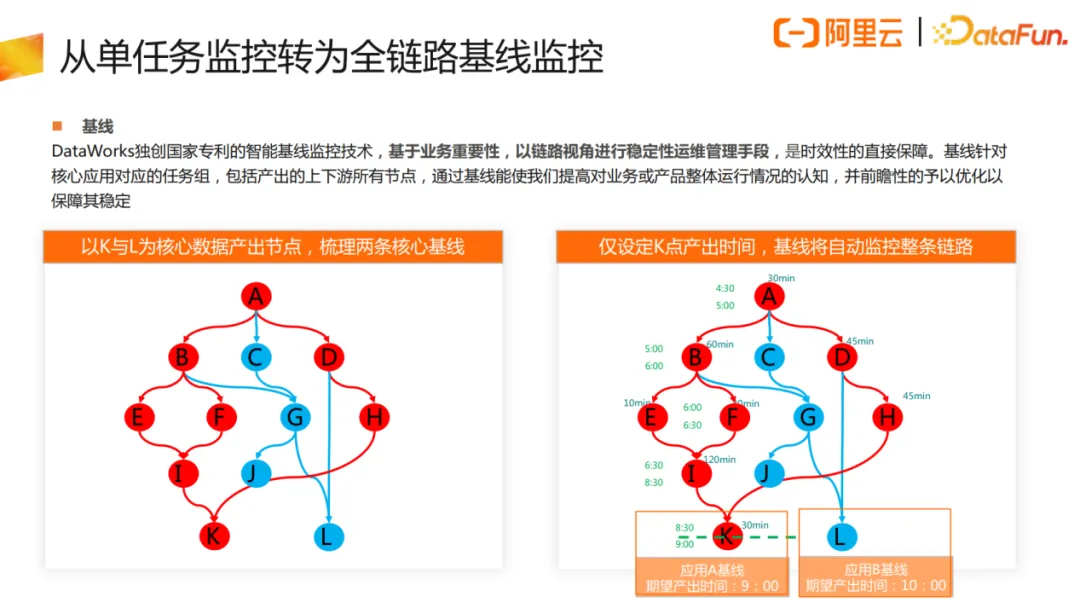
真正面向于应用去做对应的监控配置时,稳定性治理方案的最大转变,其实就是把单任务监控转为全链路的基线监控。按照业务优先级,结合全链路数据血缘梳理出与最终产出节点相关联的数据任务节点。如上图示例,图中的K节点和L节点为分别给到不同业务方的产出节点,通过血缘可以梳理出数据工作流。对应的监控,只需要在 DataWorks里面配置我们称之为基线监控的两条链路就可以。基线针对核心应用对应的任务组,包括产出的上下游所有节点。通过基线能提高对业务或产品整体运行情况的认知,并前瞻性的予以优化以保障其稳定。
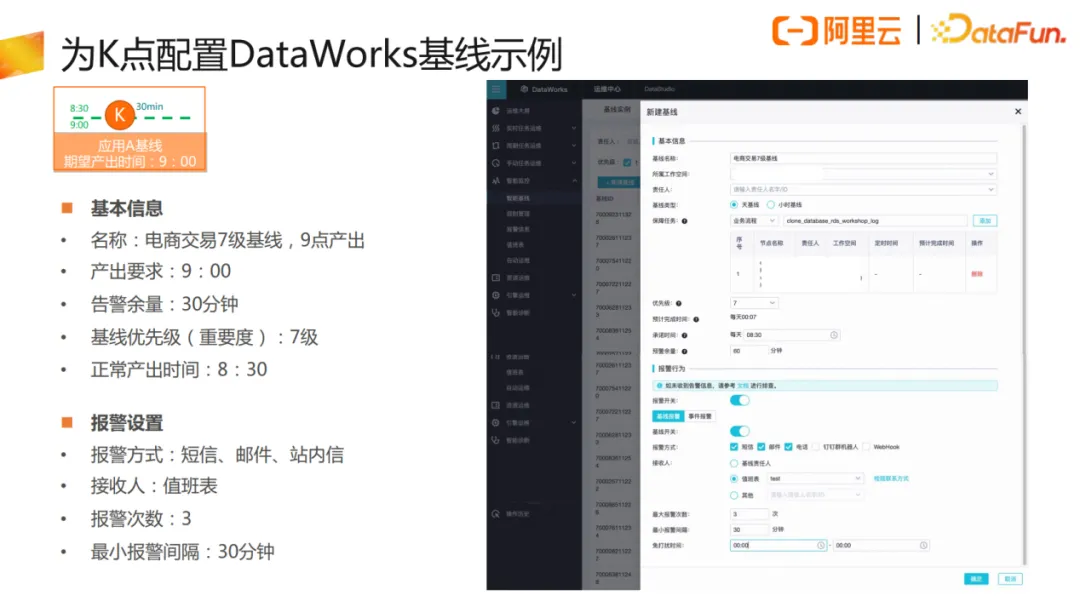
基线链路信息中包含了产出时间要求、告警余量、报警方式、接收人等。系统就会根据基线链路设定的基线优先级,识别稳定性保障重要程度,分配计算资源与调度资源。
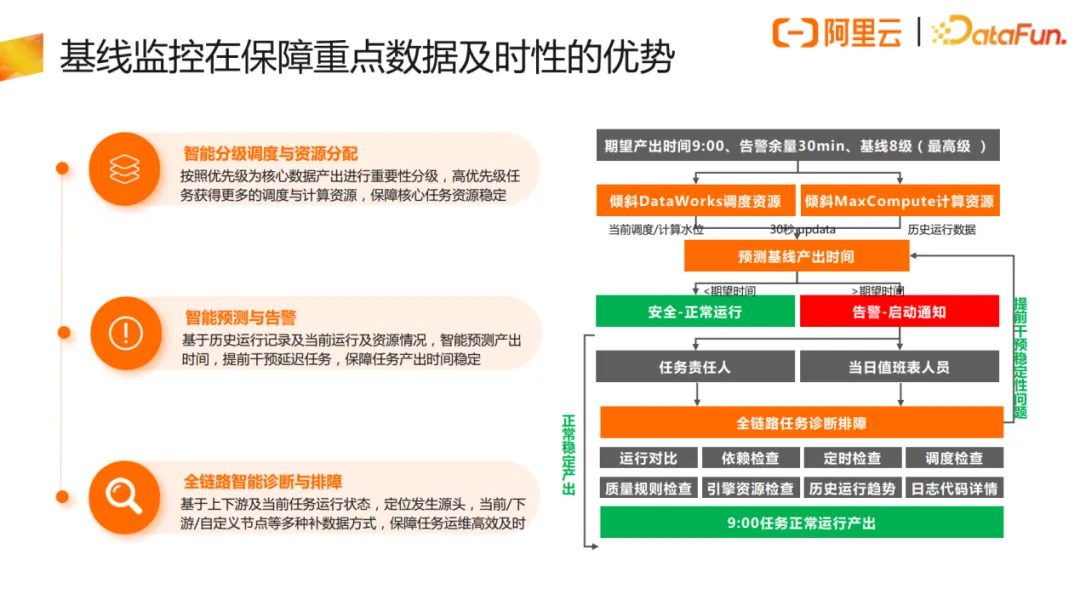
基线可保障核心任务资源稳定。按照优先级为核心数据产出进行重要性分级,高优先级任务会获得更多的调度与计算资源。平台每隔30秒会识别目前的资源情况,进行资源向重点任务倾斜与自动调整,减轻相关责任人的告警处理工作量。那如果在系统自动调整的情况下,基线任务还是没有办法按时产出,则会通知到当日的值班人员,提前干预延迟任务来保障最终的基线不会破线引起故障。
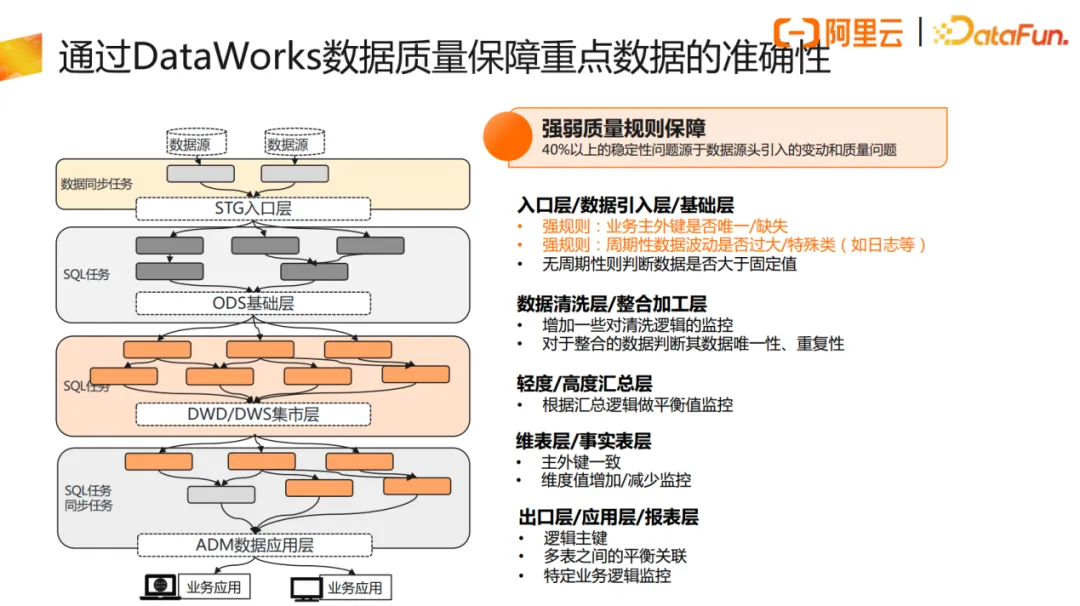
在稳定性治理方案中,除了对数据及时性的保障,还需要对数据准确性进行治理。基于以往经验,数据准确性的问题,大概40%来自于数据源头方的变动和一些数据质量问题,因此数据链路源头侧的业务数据也应引入到整体的保障机制里。通过DataWorks数据质量规则保障重点数据的准确性,在数据引入层设置好对应的监控数据稳定性相关的质量规则,如果出现了问题,则通过数据质量的强规则机制提前去阻断任务,让基线监控告警提前暴露出风险。
4. 如何实现合理的团队协同
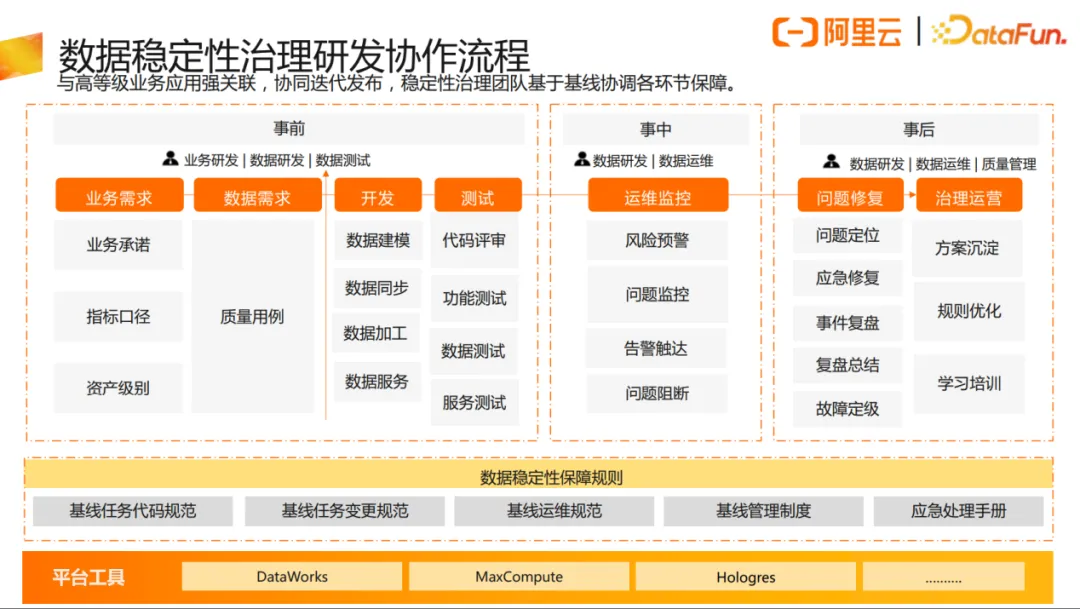
基于数据稳定性治理研发协作流程,稳定性治理团队基于基线协调各环节保障。在研发过程中,数据研发和数据测试需要对数据的稳定性进行事前保障,研发类角色与运维类角色进行事中监控,事后再与质量团队协同进行问题的复盘,共同建立各角色、各流程中有共识的数据稳定性保障规则。

同时需完善角色设置与责任认定机制。设置基线评审委员会和基线评审小组来确定基线的合理性,评审基线的等级是否合理;设置基线负责人角色,作为基线的第一责任人,进行基线的整体管理,关注基线的风险,推动任务责任人与质量负责人以及平台的资源运维方去评估风险,解决问题;设置任务负责人角色,了解运维保障的机制和规范,保障任务问题能够及时响应和处理;基线保障的业务方负责人,需为业务诉求的合理性做背书,辅助基线负责人推动基线优化落地;计算平台侧负责人,则需要关注资源情况是否符合基线的稳定性要求,执行应急运维的操作,如资源的扩容、优先级调整等。
03 阿里数据稳定性治理实践
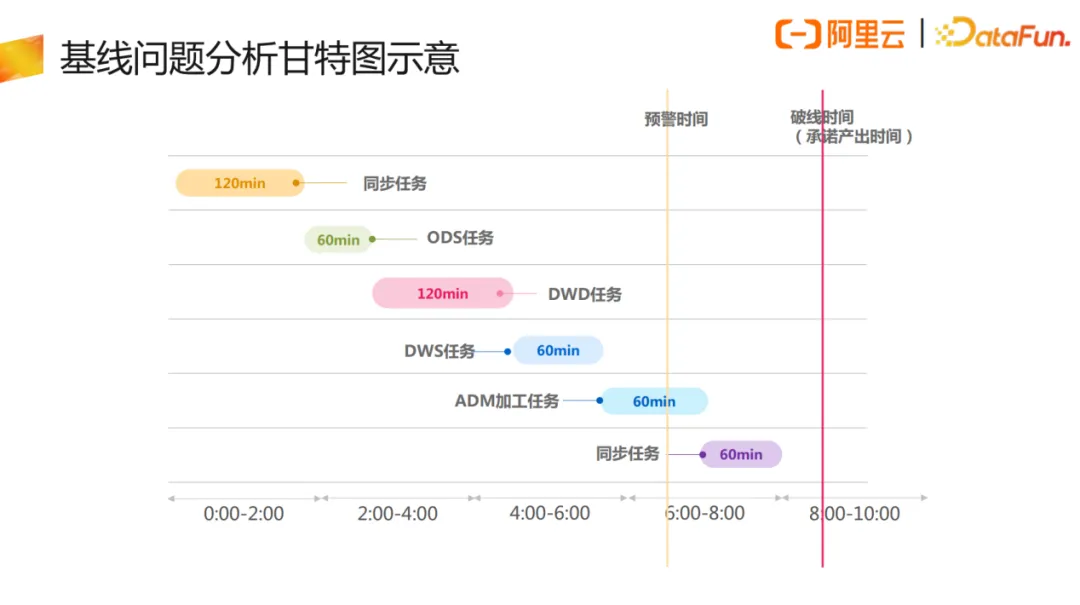
基于DataWorks的常见分析和处理手段,最直接的产品工具界面其实就是基线下链路运行的甘特图。甘特图展现了节点任务的先后顺序,每个单点任务的实际运行时间和预估运行时间、预警时间与破线时间。基于基线运维的告警一般分为两类,一是执行之前的提前预警,二是执行之后的即时告警。通过甘特图可对影响产出的超长任务、调度依赖配置错误、单点运行失败、全链路运行缓慢等问题进行识别与预警。下面是几个实例。
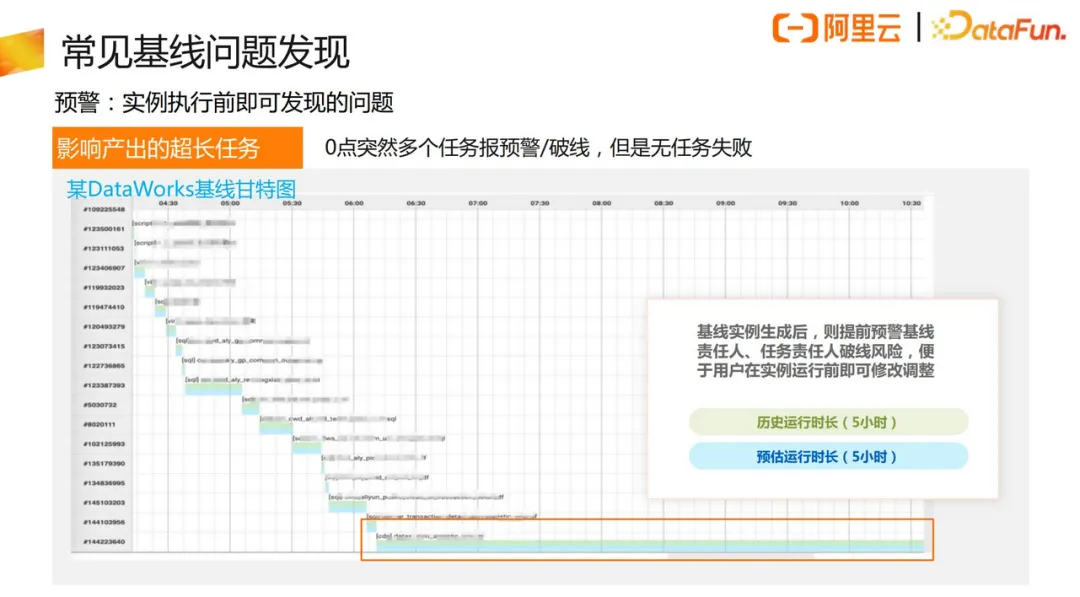
上图是一个超长任务的例子,在基线实例已经生成,但还未运行前,就对破线风险进行了预警。

上图是一个调度依赖配置错误的例子。
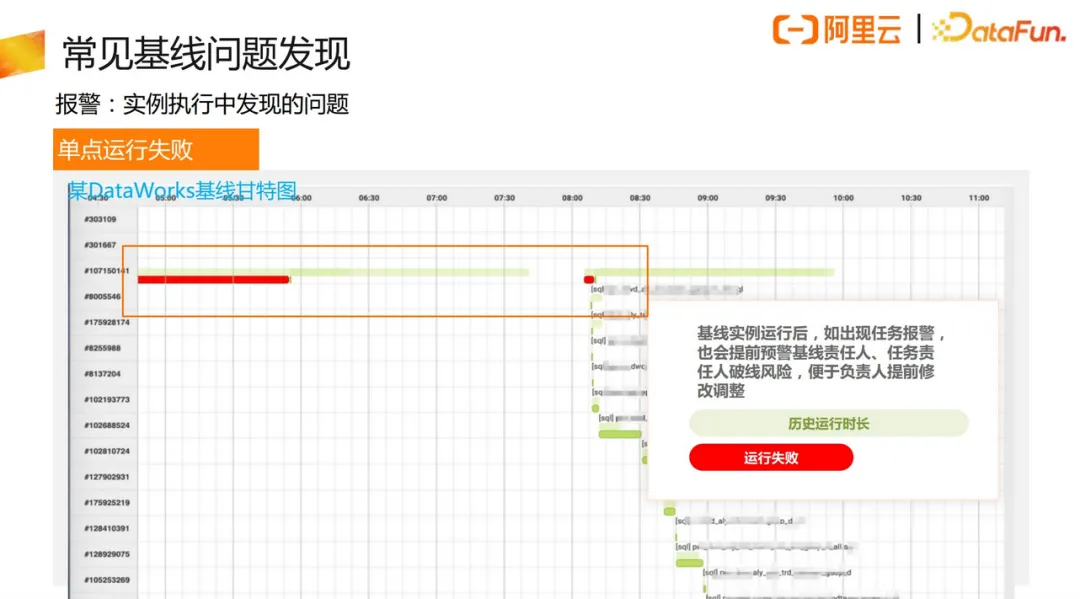
上图是实际运行中的排查,一个单点运行失败的例子。如果在历史产出时间节点前还没有处理好,就会有一些应急手段来保证数据产出。
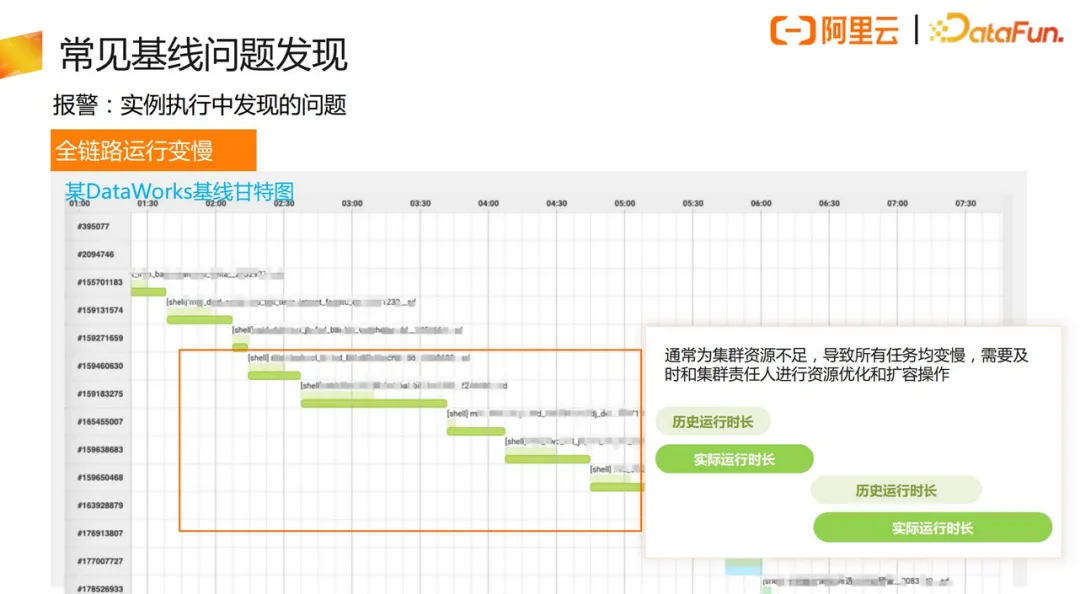
上图反应的是全链路的运行变慢,但没有特别突出的问题,通常是集群资源不足导致的,需要及时进行资源优化和扩容操作。
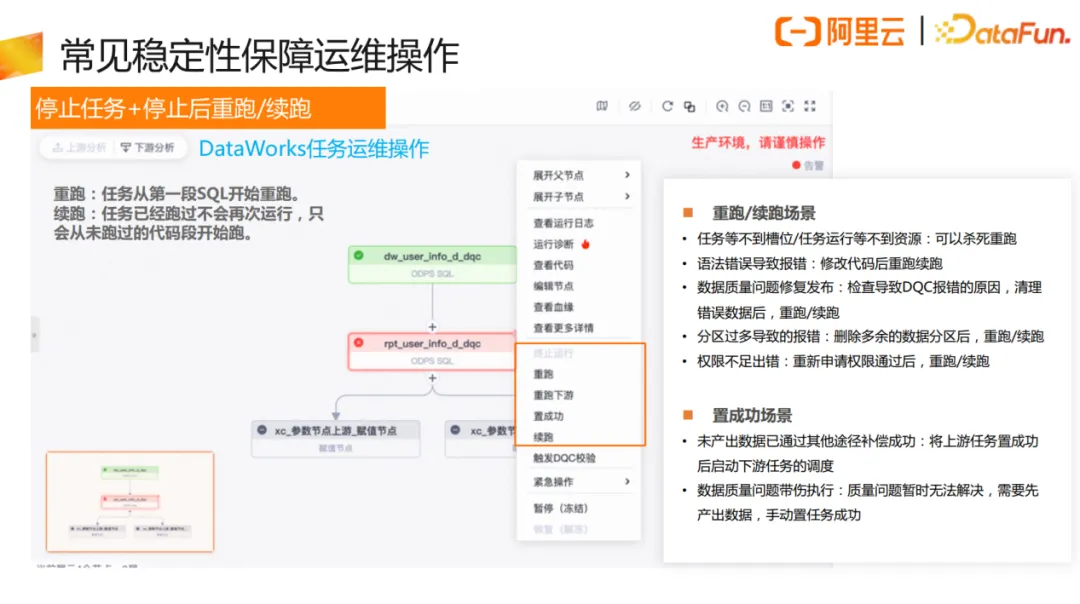

基线应用团队总结归纳了实际运维中的常用应急操作,比如停止任务、重跑、续跑、解除依赖、置成功等操作。
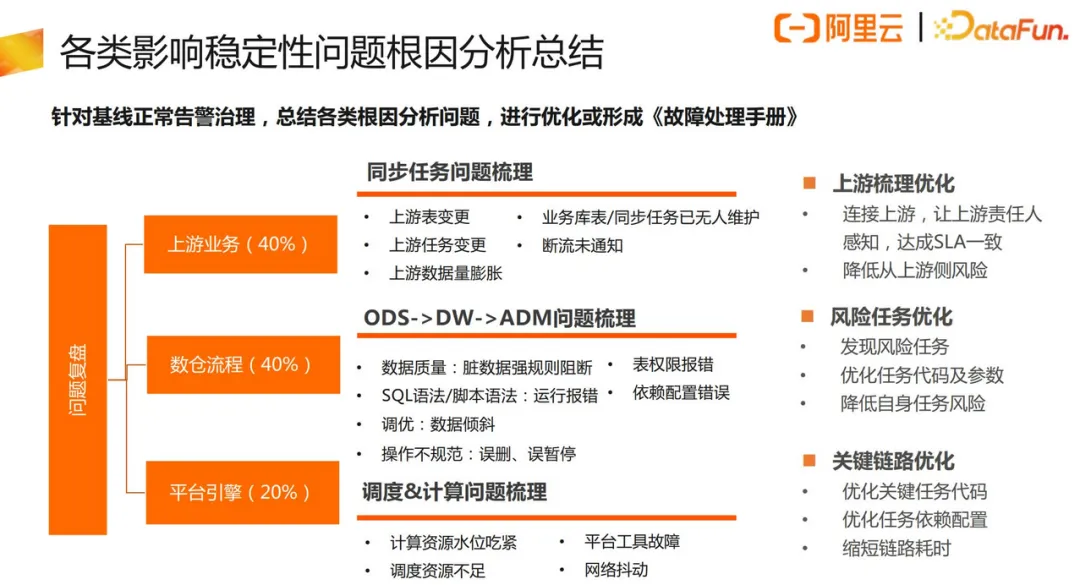
针对上游业务、数仓流程和平台引擎在日常的基线告警治理过程中出现的问题,进行了梳理和分类,找到问题根因和对应的优化方式,形成了《故障处理手册》。

评估稳定性治理的效果,两个核心指标就是基线的破线率和运维人员的起夜率。若破线率和起夜率在逐步下降,或者稳定在很低值的时候,则可以说明数据稳定性是做得较好的。
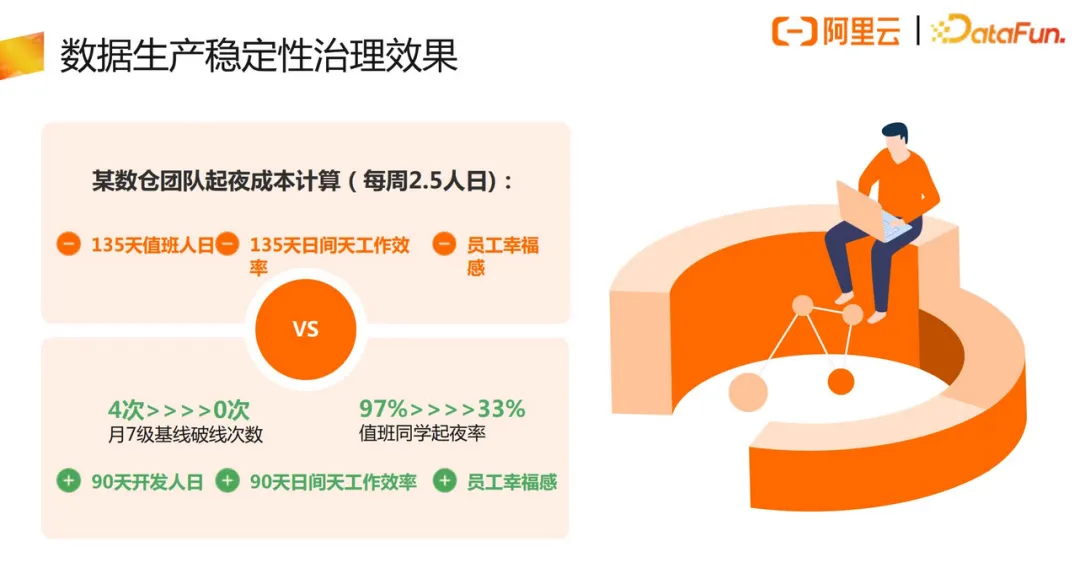
以内部某数仓团队为例,经过稳定性治理后,破线率和起夜率都大幅下降。整体数据运维和研发的效率都有了大幅提升,这就是稳定性治理的意义所在。
04
事前稳定性治理探索

稳定性问题更重要的是能在事前就进行预防和消除。治理工作在数据研发的全链路中,将实践中沉淀下来的主动化治理手段融入到各个环节中去,构建主动规范建模、主动规范校验、自动质量监控等治理策略。

事前的主动规范数据建模,需要在数据建模系统中,先设定数据标准,形成模型评审机制,明确数据指标对应的标准规范、口径与质量要求。
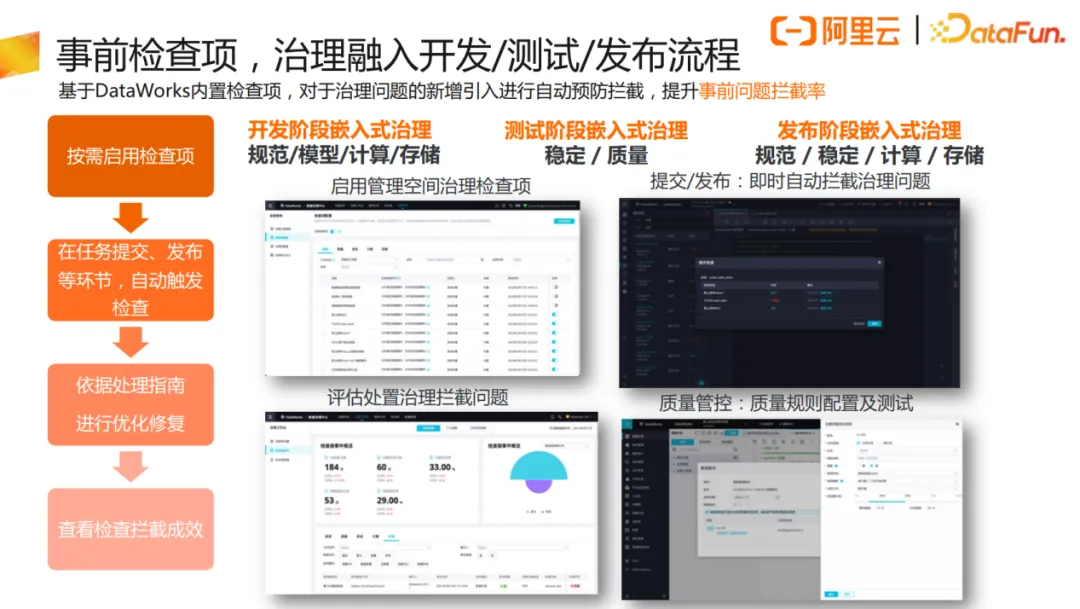
有了明确的标准要求后,可基于DataWorks数据治理中心内置检查项,对于治理问题的新增引入进行自动预防拦截,提升事前问题拦截率。

数据稳定性治理的目标为打造主动式,可量化、可持续的全链路数据治理。将DataWorks的数据治理融入开发流程,抛弃“先开发后治理”的模式,保障DataWorks的数据治理成效可量化、可持续运营,避免“应对式治理”。
我们也已将稳定性治理的经验提供给了阿里云上的用户来使用,欢迎大家来参与DataWorks相关的试用活动,希望能帮助更多企业找到更好的可落地的数据治理方案。
文章来源:“大鱼的数据人生”微信公众号